一、XPath语法简介
参考:XPath 教程
XPath是一种在XML文档中查找目标信息的语言,可以用来在XML文档中对元素和属性进行遍历。XPath使用路径表达式来选取XML文档中的节点或节点集。
在XPath中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
1、选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
下面列出了最有用的路径表达式:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
实例
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore | 选取根元素 bookstore。
注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
实例
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=’eng’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
二、XPath盲注简介
XPath盲注是代码注入中的一种,所以和SQL注入的原理基本上是一样的。XPath是能够查询XML文档的语言,类似于结构化查询语言(SQL)。事实上,许多流行的数据库允许 利用XPath来查询数据库。在许多情况下,攻击者不能够直接访问XML数据,但是,攻击者可以用部分数据来创建XPath语句,而这些语句能够用来查询XML。这样,攻击者就能够通过精心构造的输入来注入任意的查询,以此来获得数据,而这些数据在正常情况下是不允许攻击者访 问的。
XML文件能够包括信息的不同部分或者区域。有时,只有这些信息中的特定部分才会被暴露给最终用户,例如,下述XML包含了姓名和社会保障号:
<?xmlversion='1.0'?>
<staff>
<author>
<name>Tom Gallagher</name>
<SSN>123-45-6789</SSN>
</author>
<author>
<name>Bryan Jeffries</name>
<SSN>234-56-7890</SSN>
</author>
<author>
<name>Lawrence Landauer</name>
<SSN>012-345-6789</SSN>
</author>
</staff>
这个XML存储在一个Web服务器上,并且是不能够被最终用户直接访问的。在这个服务器上用于查询XML的一个网页是能够被最终用户访问的,而且,只有作者姓名能够通过网页进行显示。利用下述XPath表达式就能够获得XML数据:
//*[contains(name,'Attacker-Data')]/name
Attacker-Data是最终用户指定的数据,正如你所看到的那样,攻击者能够控制部分XPath查询。通过指定数 据为x’)] | //*| //*[contains(name,’y,攻击者能够获得这个XML文件的完整内容。这种输入构造了如下的XPath表达式:
//*[contains(name,’x’)] | //*| //*[contains(name,’y’)]/name
注意在上述表达式中,管道符号(|)用于表示或操作,左斜线和一个星号(//*)代表所有节点。上述XPath表达式可能有下述三种情况:
1.任何包含x的姓名
2.任何在这个XML文件中的节点
3.任何包含y的姓名
因为在第二种情况下能够返回所有节点,所以攻击者能够获得这个XML文件的所有数据!
ps:上述XPath盲注类似与SQL注入中的’ or 1=1 or ‘。
三、XPath盲注实例
hctf2015 的web题目中的第一题就是考察的XPath盲注。该题的源代码:
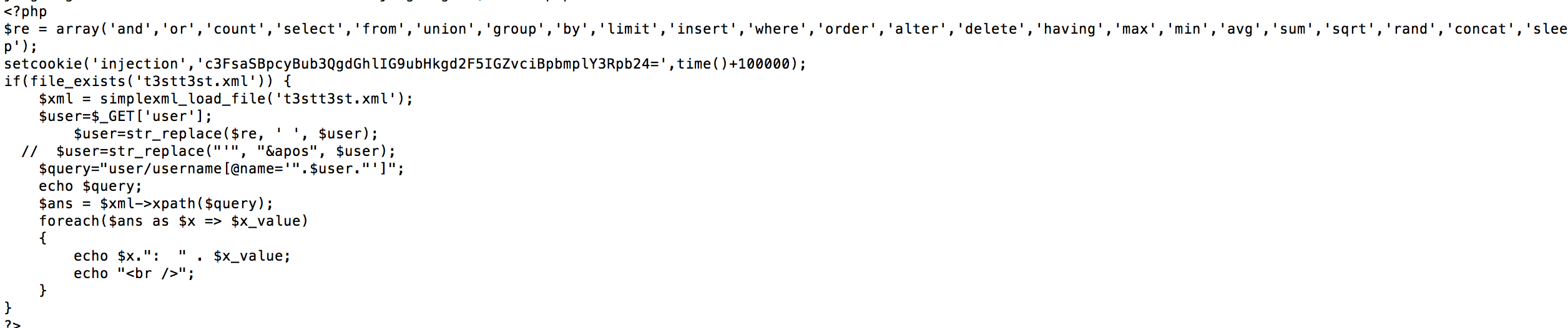
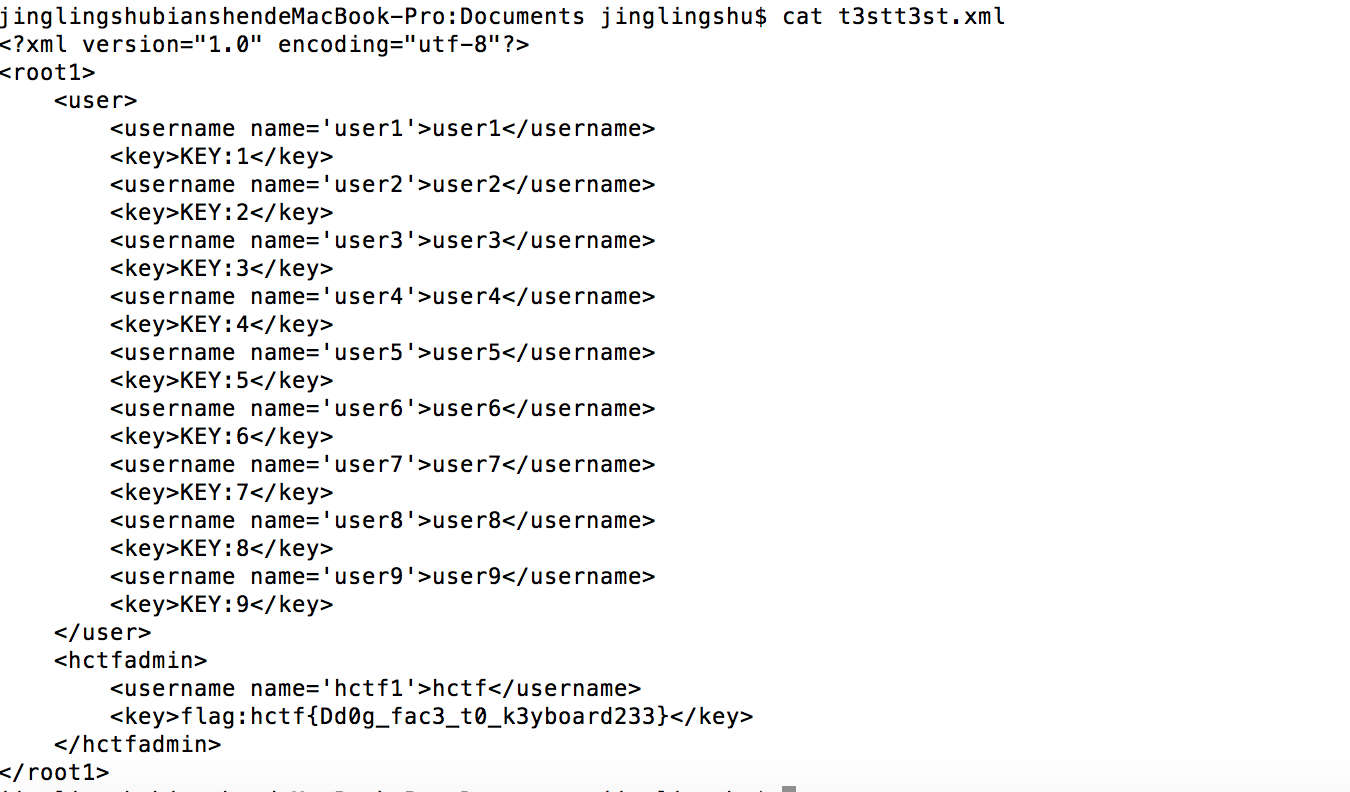
其中 其中t3stt3st.xml的文件内容为:
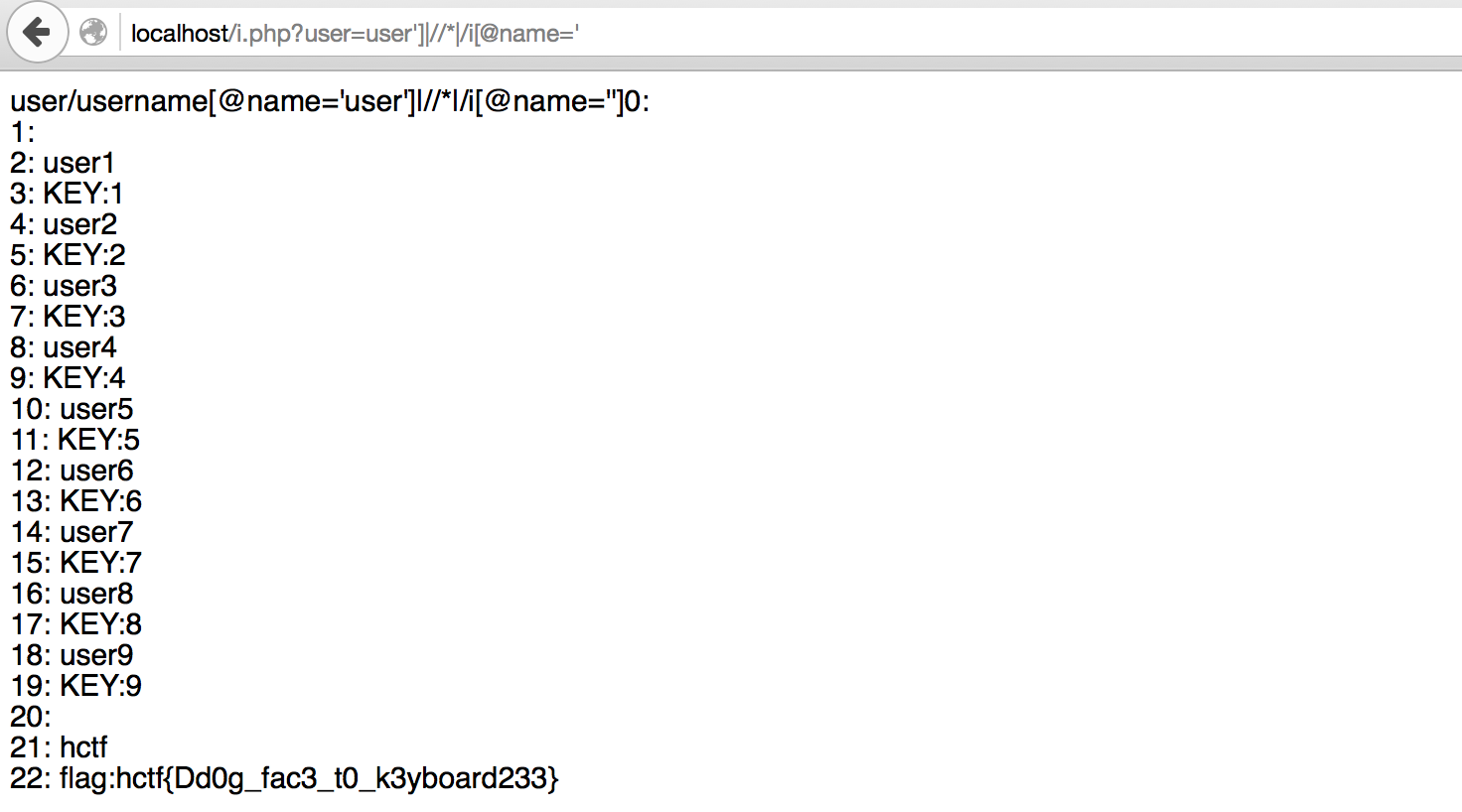
参考资料:
1、https://github.com/hduisa/hctf2015-all-problems/tree/master/injection
3、XPath 教程
转载请注明:jinglingshu的博客 » XPath盲注学习