转自:http://www.arkteam.net/?p=4066
作者:{WJN}@ArkTeam
原文标题:Learning to Evade Static PE Machine Learning Malware Models via Reinforcement Learning
原文作者:Hyrum S. Anderson, Anant Kharkar, Bobby Filar, David Evans, Phil Roth
原文出处:https://arxiv.org/pdf/1801.08917
(前导文章曾在BlakHat会议上展示,链接为https://www.blackhat.com/docs/us-17/thursday/us-17-Anderson-Bot-Vs-Bot-Evading-Machine-Learning-Malware-Detection-wp.pdf )
机器学习常常应用于恶意软件检测,因为它具备检测未知恶意软件家族和恶意软件多态的能力。然而最近在对抗性机器学习方面的研究表明,深度学习模型容易受到基于梯度的攻击。
在本文中,作者提出了一个基于强化学习(RL)的更通用的框架,用于攻击静态可移植可执行(PE)恶意软件检测系统。该框架不需要可靠的模型,也不需要目标系统产生分数。相反,RL代理程序配备了一组可在PE文件上执行的功能保留操作。通过针对目标恶意软件检测系统的一系列交互,即可了解哪些操作序列可能导致避开任何给定恶意软件样本的检测。这样可以对静态PE恶意软件检测系统进行完全黑盒攻击,并直接产生功能性回避的恶意软件样本。
一、强化学习简介
强化学习模型由代理和环境组成,他们在一系列轮转(或离散时间步长)中相互作用。对于每个轮转t,代理可以基于策略π(a | st)和可观察的环境状态向量st选择动作a∈A。环境产生奖励rt∈R以响应所选择的动作以及新的环境状态向量st+1。将环境st+1的奖励rt和观察状态反馈给代理,以基于策略π(a | st+1)选择新动作。代理人通过勘探和利用的妥协平衡逐渐学习,根据环境的状态产生行动。代理的目标是学习导出一个策略,该策略最大化由Vπ(st)= E at [Qπ(st,at)| st]定义的预期收益。通过Vπ促进不会立即产生奖励但对最终结果很重要的早期行动,这可以预测给定状态的长期回报。该函数估计对给定状态采取给定动作的预期效用称为Q函数。
二、实验场景映射
在实验中,作者训练ACER代理(actor-critic model with experience replay)来学习图1所示框架的策略。在所示的Markov决策过程中,代理获得环境状态s∈S的估计,由恶意软件的特征向量s表示(不需要与目标恶意软件检测系统的恶意软件的任何内部表示相对应)。 Q函数和行动政策决定采取什么行动。
在我们的框架中,动作空间A包含一组对PE文件的修改,它们(a)不破坏PE文件格式,(b)不改变恶意软件样本的预期功能。
奖励函数由恶意软件检测系统度量,如果被修改的恶意软件样本被判定为恶意(无逃避),则奖励为0;如果被认为是良性(逃避)则为R。然后将奖励和状态反馈给代理。
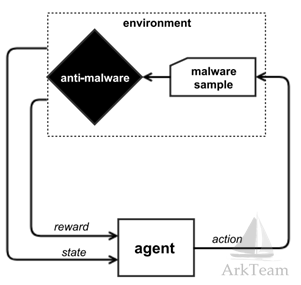
图1 系统架构图
- Anti-malware
对100,000个恶意和良性样本进行训练的梯度增强决策树模型。
2. State
恶意软件样本在环境中以原始字节存在。但是,为了更简洁地表示恶意软件样本的当前状态,环境以特征向量的形式反馈状态。在实验中,作者使用2350维特征向量,该向量由以下一般类别的特征组成:
•PE标头元数据
•节元数据:节名称,大小和特征
•导入和导出表元数据
•人类可读字符串的计数(例如文件路径,URL和注册表项名称)
•字节直方图
•2D字节熵直方图
3. action
环境中代理可采取动作的含义为对PE文件进行适度的不会破坏PE文件格式并且不会改变代码执行的修改。文章中采取的动作包括但不限于:
•将函数添加到从未使用的导入地址表中
•操纵现有的section的名称
•创建新的(未使用的)section
•在节的末尾将字节附加到额外的空格
•创建一个新的入口点,立即跳转到原始入口点
•删除签名者信息
•操纵调试信息
•包装或拆包
•修改(中断)头部校验和
•将字节附加到叠加层(PE文件的末尾)
本文所实现的是最具挑战性的攻击方案,即攻击者可以获得的信息有限制:
(1)目标分类器的输出是严格的布尔值,仅表明分类器认为样本是良性或恶意。
(2)目标分类的特征空间和结构完全未知。
(3)没有第三方(例如oracle)来保证样本有效。
三、实验结果展示
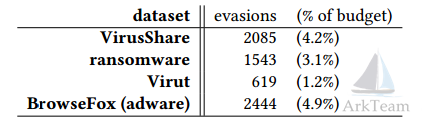
表1 在培训期间发现的规避变种的数量
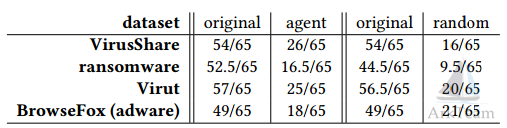
表2 交叉逃避
作者将强化学习代理产生的样本上传到VirusTotal,发现与原始样本的检测率相比,中值检测率下降。该结果说明通过绕过相对简单的机器学习模型,造成商业产品的交叉逃避是可能的。