
我每天需要处理大量的文章。
社交媒体推荐的文章、RSS 订阅的文章、主动搜索到的文章…
因为有大量的信息要处理,我的 read it later 文章也越来越多。两年多来,我的 cubox 里的待读文章,已经攒到了 4800 篇。
但我并不会为此感到焦虑,这些文章成了一个经过我筛选的“图书馆”,当我需要的时候,我可以在里面找到自己想要的文章进行阅读。
在没有 AI 之前,我的文章处理步骤是这样的:
- 粗略阅读,筛选信息
- 经过筛选的信息,阅读其中一部分/全文阅读
- 阅读过后记录「文献笔记」
具体的步骤可以参考我在 2021 年写的《我的阅读工作流(2021版)》
有了AI 以后,大语言模型(LLM)可以帮助我们处理文章,提高筛选文章和阅读文章的效率。
下面我将介绍我使用 AI 来帮助我提高文章阅读效率的方法。
我称之为「AI渐进式阅读法」
AI渐进式阅读法
模型选择
首先先选择大模型,我选择的是 Kimi Chat
- 而对比国内的一众大模型厂商,Kimichat 的长文本能力(long-context)是最好的。文章一般的字数一般都比较多,依赖大模型的长文本能力来处理。
- 对比海外的大模型,比如同样支持操场文本的 Claude ,Kimi Chat 对中文的支持更好。
- Kimi Chat 现在可以免费使用,并且支持 Web、H5、APP、微信小程序等多终端,哪里都能用。
第一步 了解文章
人工处理文章时,我需要对文章进行判断:
- 判断信息质量,只读高质量文章
- 是否是自己需要的?读完能学到什么?
- 是否是当下需要的?不是当下需要的,先存起来,”read it later“。
参考人工处理文章的步骤
第一步,我们可以让 AI 帮我们先读一遍文章,了解文章的基础信息。
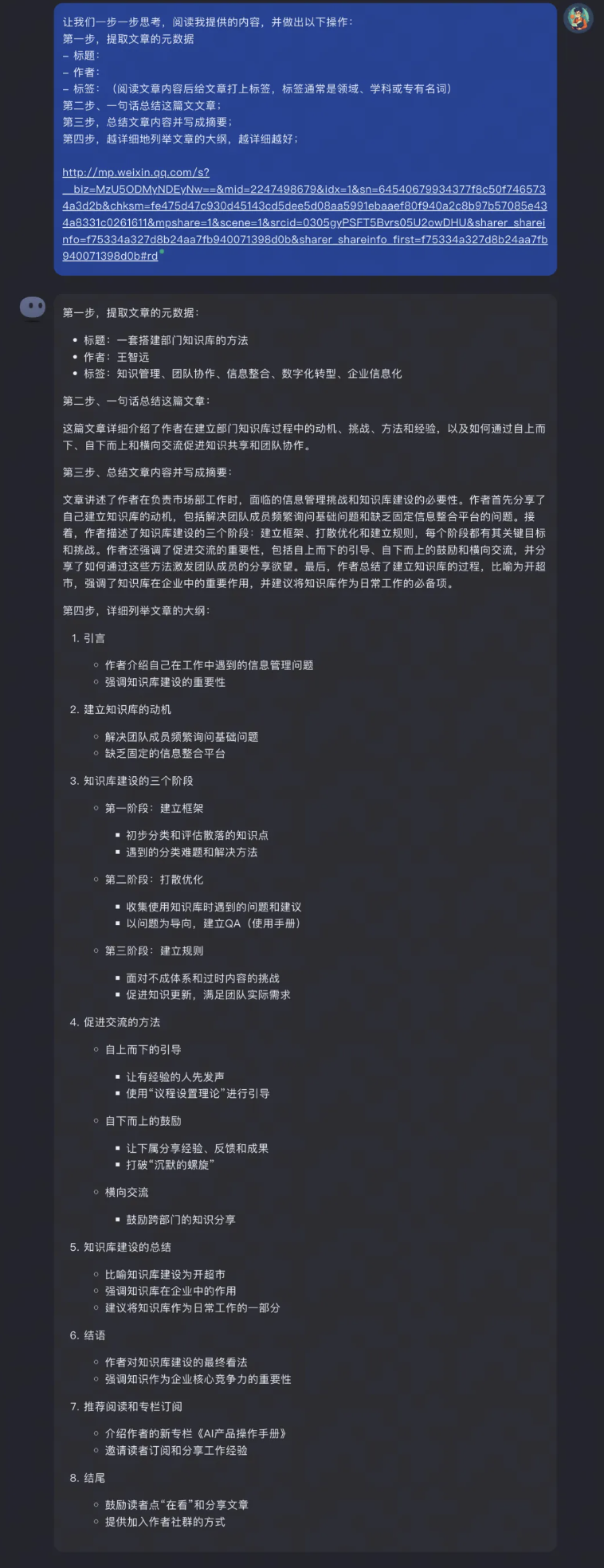
在第一步的 prompt 里,为了更好地了解文章,我让 AI 帮我总结了文章的元数据,包括标题、作者和标签;一句话总结文章,再写了摘要,我只要阅读这部分,就可以大概知道文章讲的是什么。;详细列举文章的大纲,通过大纲的阅读,就可以知道文章的结构。
以这篇文章《一套搭建部门知识库的方法》为例
使用以下 prompt 发给 kimichat
<span role="presentation">让我们一步一步思考,阅读我提供的内容,并做出以下操作:</span>
<span role="presentation">第一步,提取文章的元数据</span>
<span role="presentation">- 标题:</span>
<span role="presentation">- 作者:</span>
<span role="presentation">- 标签:(阅读文章内容后给文章打上标签,标签通常是领域、学科或专有名词)</span>
<span role="presentation">第二步、一句话总结这篇文文章;</span>
<span role="presentation">第三步,总结文章内容并写成摘要;</span>
<span role="presentation">第四步,越详细地列举文章的大纲,越详细越好;</span>
<span role="presentation">{{文章链接}}</span>
得到结果:
第二步 详读文章
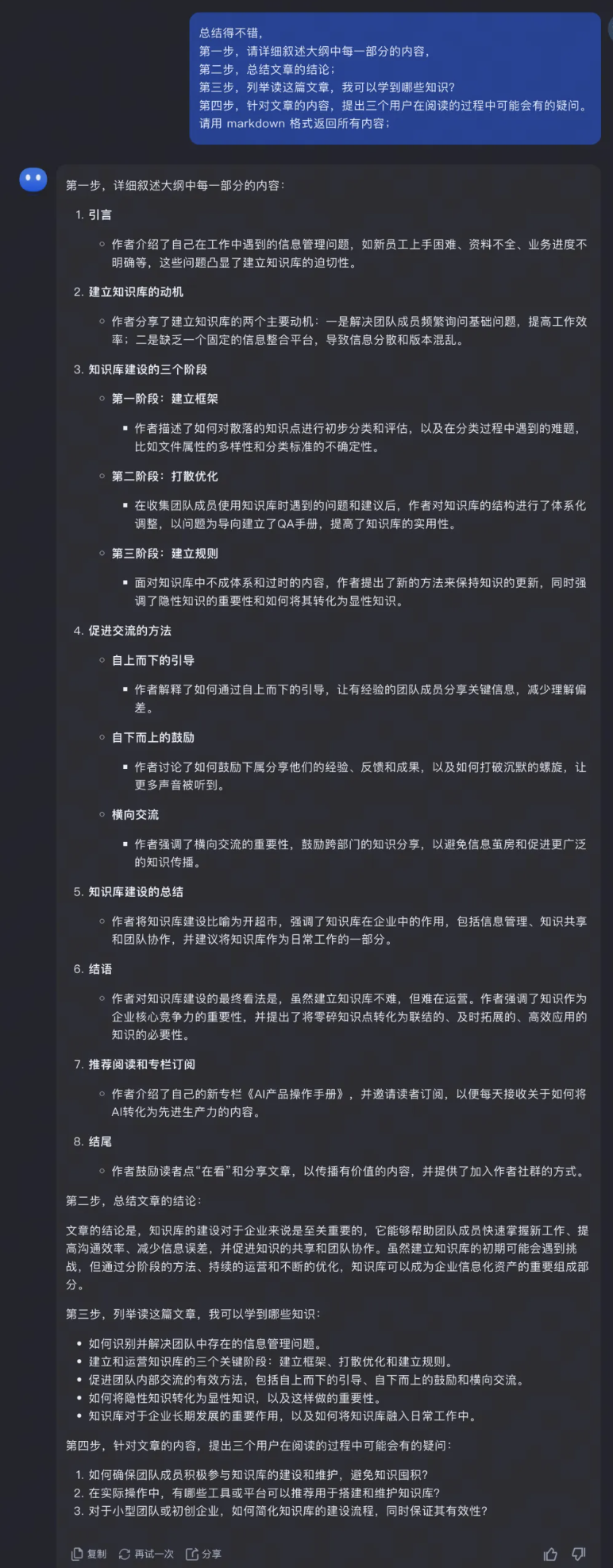
在阅读了第一步的结果的基础上,紧接着继续追问
- 详细总结文章每一部分的内容
- 我总结了文章的结论
- 告诉我阅读这篇文章我可以学到什么?
- 提供阅读文章的过程中,读者可能会有的疑问。帮助我更好地进行第三步的进阶阅读。
<span role="presentation">总结得不错,</span> <span role="presentation">第一步,请详细叙述大纲中每一部分的内容,</span> <span role="presentation">第二步,总结文章的结论;</span> <span role="presentation">第三步,列举读这篇文章,我可以学到哪些知识?</span> <span role="presentation">第四步,针对文章的内容,提出三个用户在阅读的过程中可能会有的疑问。</span> <span role="presentation">请用 markdown 格式返回所有内容;</span>
第三步 个性化进阶阅读
01 对不懂的内容进行追问
02 专有名词解释
03 用高中生可以听懂的语言解释 XXX
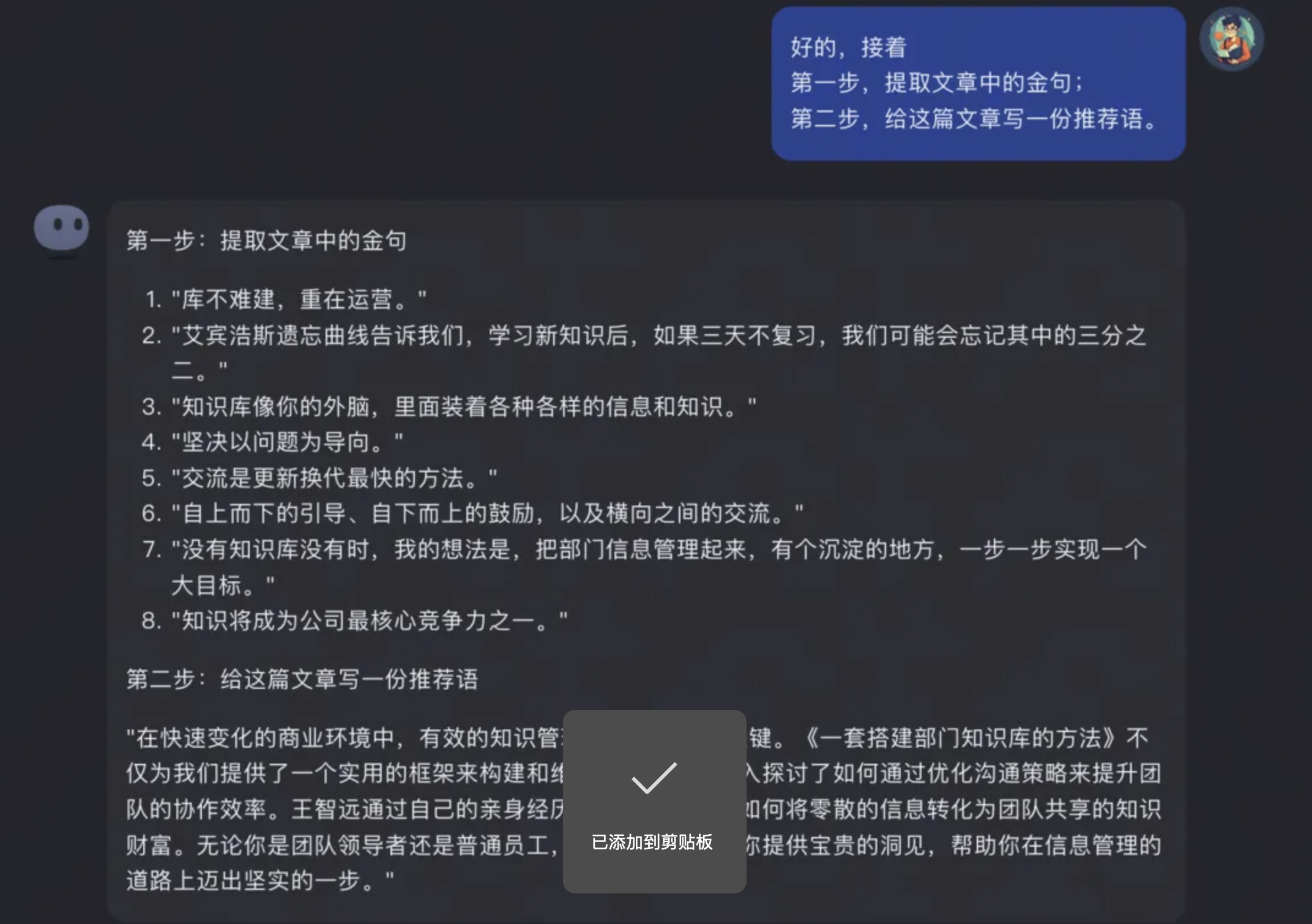
04 提取金句和写推荐语
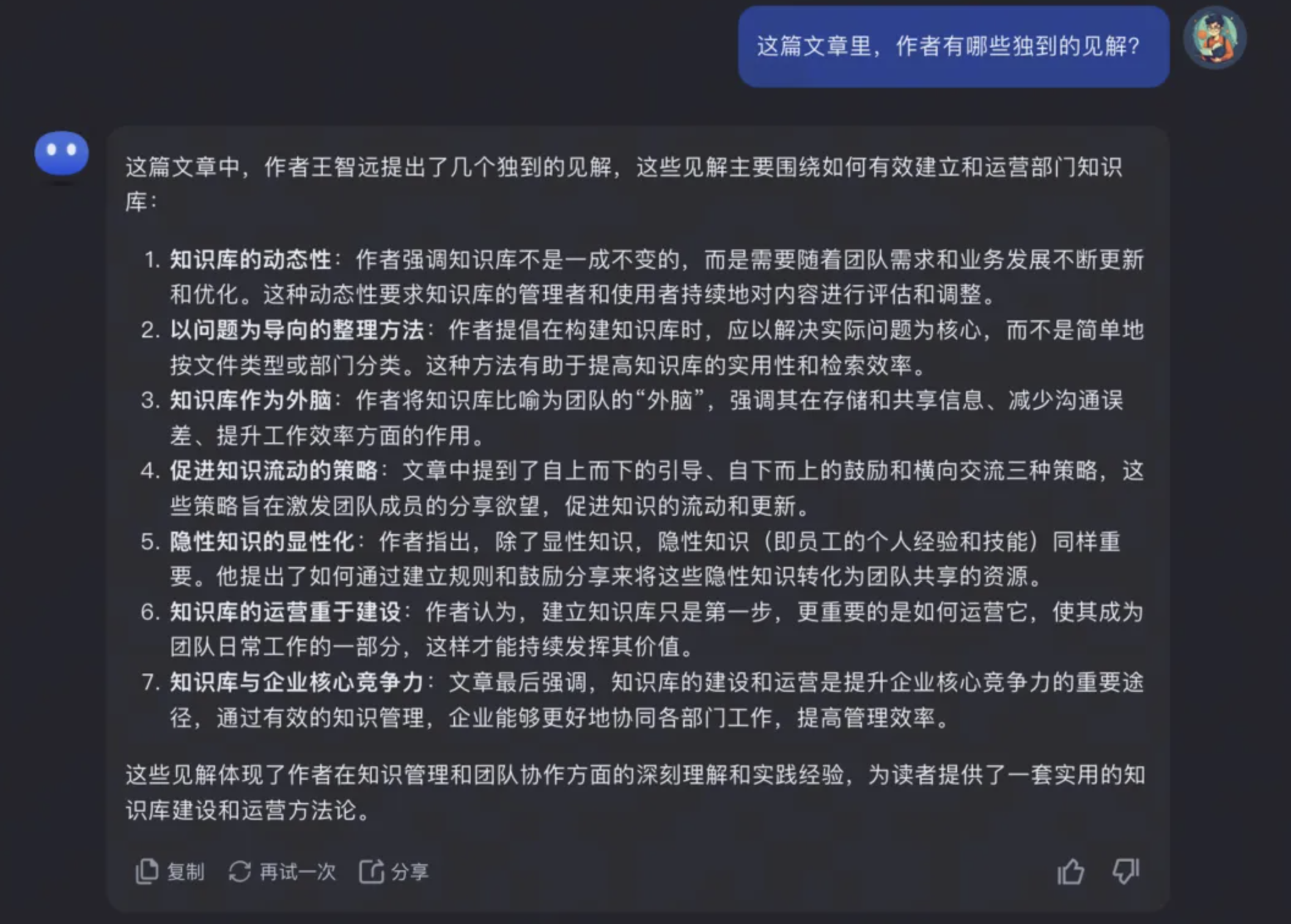
05 作者独到的见解?
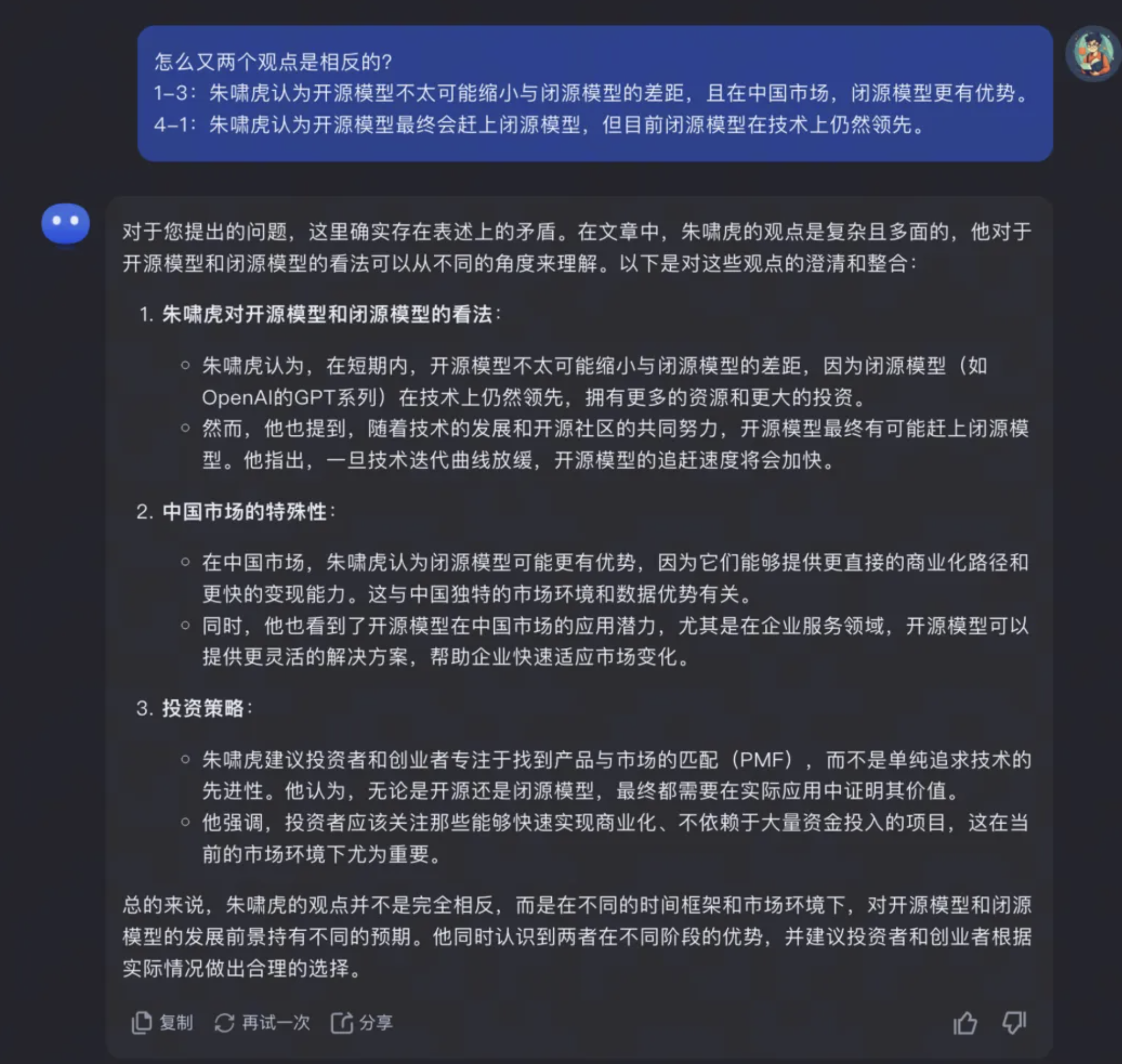
06 XXX观点在原文中的描述是什么?请打印出来

- AI 只根据文字的数量来评估内容的重要性,有时候会误判。例如在某篇”打假”的文章中,因为文章中提出了大量虚假的案例,AI 总结时反而误以为这些案例是在支撑这个“虚假的观点”,总结出了和文章完全相反的内容。
- AI 总结存在一定幻觉,不同的模型效果不同,像 KIMICHAT 这样对 long-context 支持比较好的模型,效果相对来说会比较好。当然,长远来说,幻觉的问题都会随着 LLM 的能力增强而变得不再是个问题。
- AI 更擅长处理结构化的信息,而在面对非结构化信息时,总结效果较差。例如,AI 在总结访谈类内容,会议记录这样口语化的内容时,总结的效果会稍差一些。需要使用其他的格式的 prompt 来处理。这个 prompt 目前我还在研究中,欢迎有会议总结处理,访谈内容处理经验的同学分享你的 prompt。
总结
- 第一步是让AI阅读文章,提取元数据、一句话总结、写摘要和列举大纲。
- 第二步是在第一步的基础上,让AI详细总结文章内容、总结结论、列举学到的知识点和提出可能的疑问。
- 第三步是个性化的进阶阅读,根据个人需要向AI发出指令,如追问不懂的问题、解释专有名词、简化复杂概念等。