01 背景
为保障k8s集群的安全性,我们购买了某云厂商的容器安全产品。其中有一项”隔离容器“功能是:假如某个pod有漏洞,被黑客入侵了,容器安全可以对其进行一键快速隔离,以阻止其向其他pod扩散或逃逸到node节点。本文的目的探寻容器安全隔离功能的实现原理并进行验证,从而进一步明确该功能在生产环境中对业务的影响。
02 操作界面
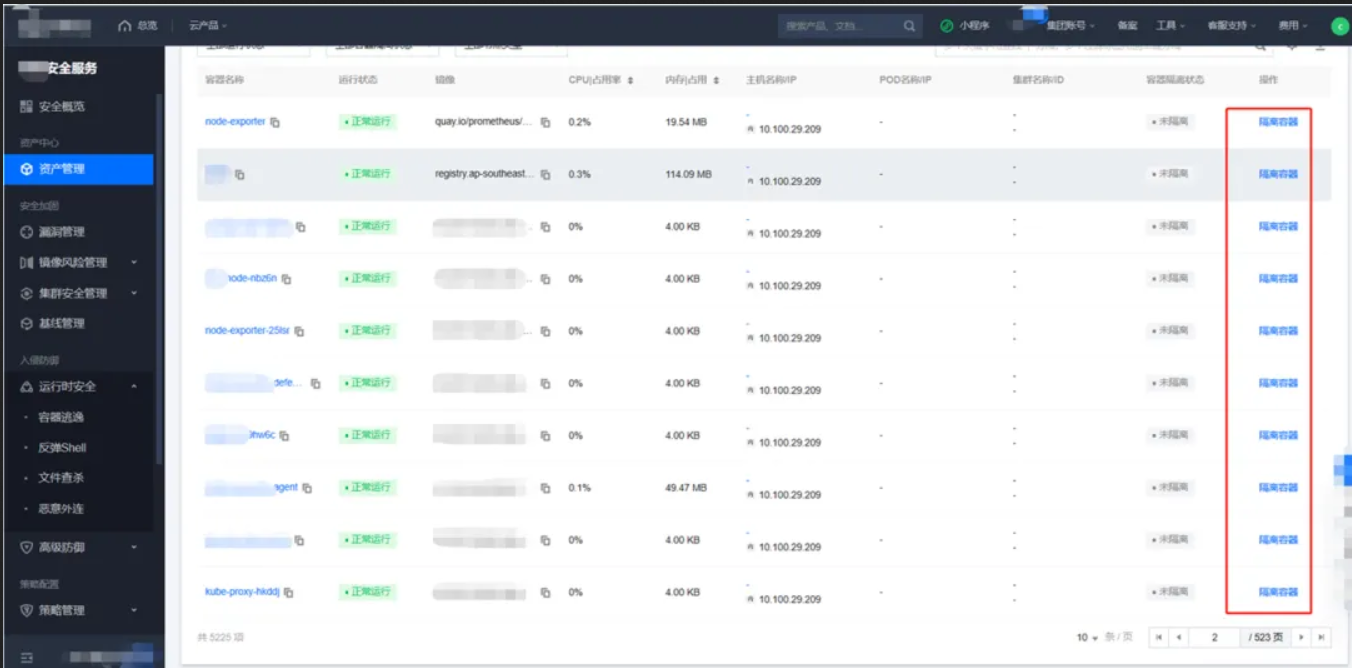

03 隔离原理
在容器net namespace 里增加iptables规则,拒绝所有流量。
~]# nsenter --net=/proc/$pid/ns/net iptables -nL Chain INPUT (policy ACCEPT) target prot opt source destination test-nips all -- 0.0.0.0/0 0.0.0.0/0 Chain FORWARD (policy ACCEPT) target prot opt source destination Chain OUTPUT (policy ACCEPT) target prot opt source destination Chain test-nips (1 references) target prot opt source destination DROP all -- 0.0.0.0/0 0.0.0.0/0
04 目的
1.验证容器隔离的功能和效果;
2.明确该功能在生产环境中对业务的影响;
05 问题和结论
01. 隔离的效果是什么?
答:被隔离的pod内被所有的容器网络断开。。
02. 隔离原理是什么,通过什么技术手段进行隔离?
答:通过进入到pod net namespace 里增加iptables规则,拒绝所有流量。
03.隔离容器之后,pod的表现是什么?
答:
表现1:pod内被隔离的容器网络被完全隔离,无法对外提供服务,也无法访问外部。
表现2:容器可能重启,取决于是否配置了livenessProbe.
情况①:容器没有配置livenessProbe,容器不会重启,只是网络被隔断。
情况②:容器配置了livenessProbe,kubelet对其探测会失败,容器会被不断进行重启。
04. 是否会重新拉起新的pod?
答:不会,因为pod总数没有变化。
05. 隔离容器之后是否对业务有影响?
答:可能会受影响。隔离之后容器无法正常工作,是否对业务造成影响取决于总的pod副本数和被隔离的容器数量。
如果deployment 有多个pod副本,隔离了部分pod之后,仍能正常工作,则业务不受影响。
如果deployment 仅有1个pod, 或虽然有多个pod副本,但隔离了之后,整个服务无法正常工作,则业务会受到影响。
06. 隔离之后能否保留现场?
答:同样,取决于是否配置了livenessProbe,如果没有配置了livenessProbe,容器不会重启,里面的所有文件都将保留。
如果配置了livenessProbe,容器会被重启,重启后是全新的容器,里面的所有文件无法保留。
06 测试和验证过程
01. 测试环境
启动一个的deployment,包含2个容器,其中1个容器配置的liveness。

test-nginx.yaml
test-nginx.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
livenessProbe:
tcpSocket:
port: 80
- image: centos:7
name: centos
command: ["/bin/sleep"]
args: ["600000"]
02.开始验证
隔离之前
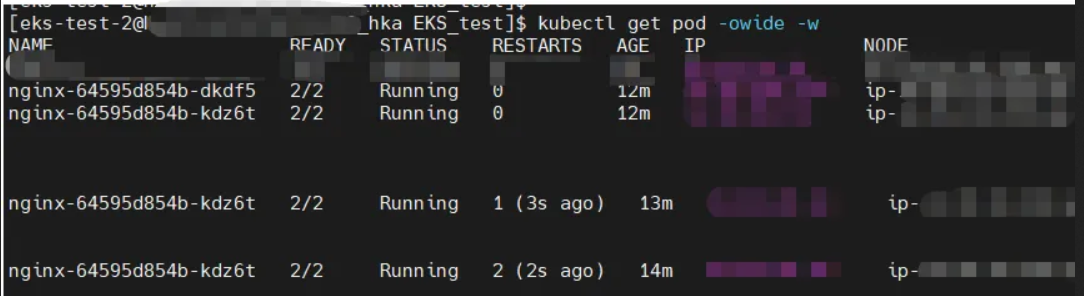
执行kubectl apply -f test-nginx.yaml 之后,可以看到两个pod均正常运行。

ssh到其中1个pod(第2个) 所在的node节点上可以看到运行了2个容器。

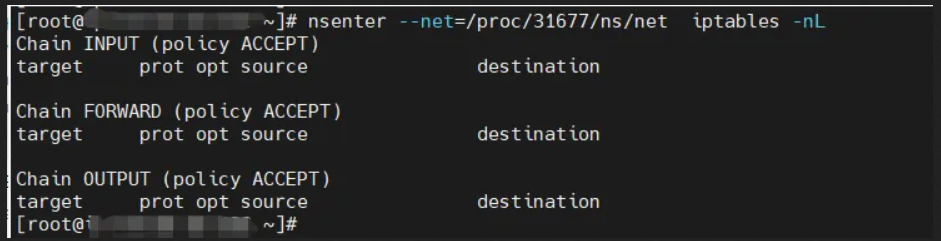
检查和确认这2个容器共享同一个net namespace,其中31677是pause的pid

隔离之前,进入31677的net namespace, 可以看到没有Iptables规则。
隔离之后
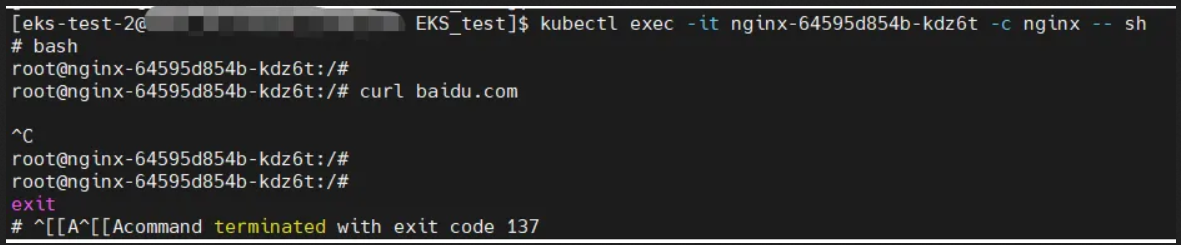
隔离之后,pod里的nginx容器因配置了liveness,在健康探测失败后触发了重启。
进入centos容器,验证无法访问外部域名

进入nginx容器,同样无法访问外部域名
进入容器的31677的net namespace,检查iptables规则。存在一条拒绝所有的iptables规则。
~]# nsenter --net=/proc/31677/ns/net iptables -nL Chain INPUT (policy ACCEPT) target prot opt source destination **-nips all -- 0.0.0.0/0 0.0.0.0/0 Chain FORWARD (policy ACCEPT) target prot opt source destination Chain OUTPUT (policy ACCEPT) target prot opt source destination Chain **-nips (1 references) target prot opt source destination DROP all -- 0.0.0.0/0 0.0.0.0/0
能否保留现场?
同样,这取决于是否配置了livenessProbe,如果没有配置了livenessProbe,容器不会重启,里面的所有文件都将保留。
如果配置了livenessProbe,容器会被重启,重启后是全新的容器,里面的所有文件无法保留。
隔离之前,写入一个测试文件。

隔离之后,因容器发生了重启,容器里没有保留上述测试文件。

作者:陈兴
来源-微信公众号:三七互娱技术团队
出处:https://mp.weixin.qq.com/s/BA05f19hmIG3xKxYysdK9g
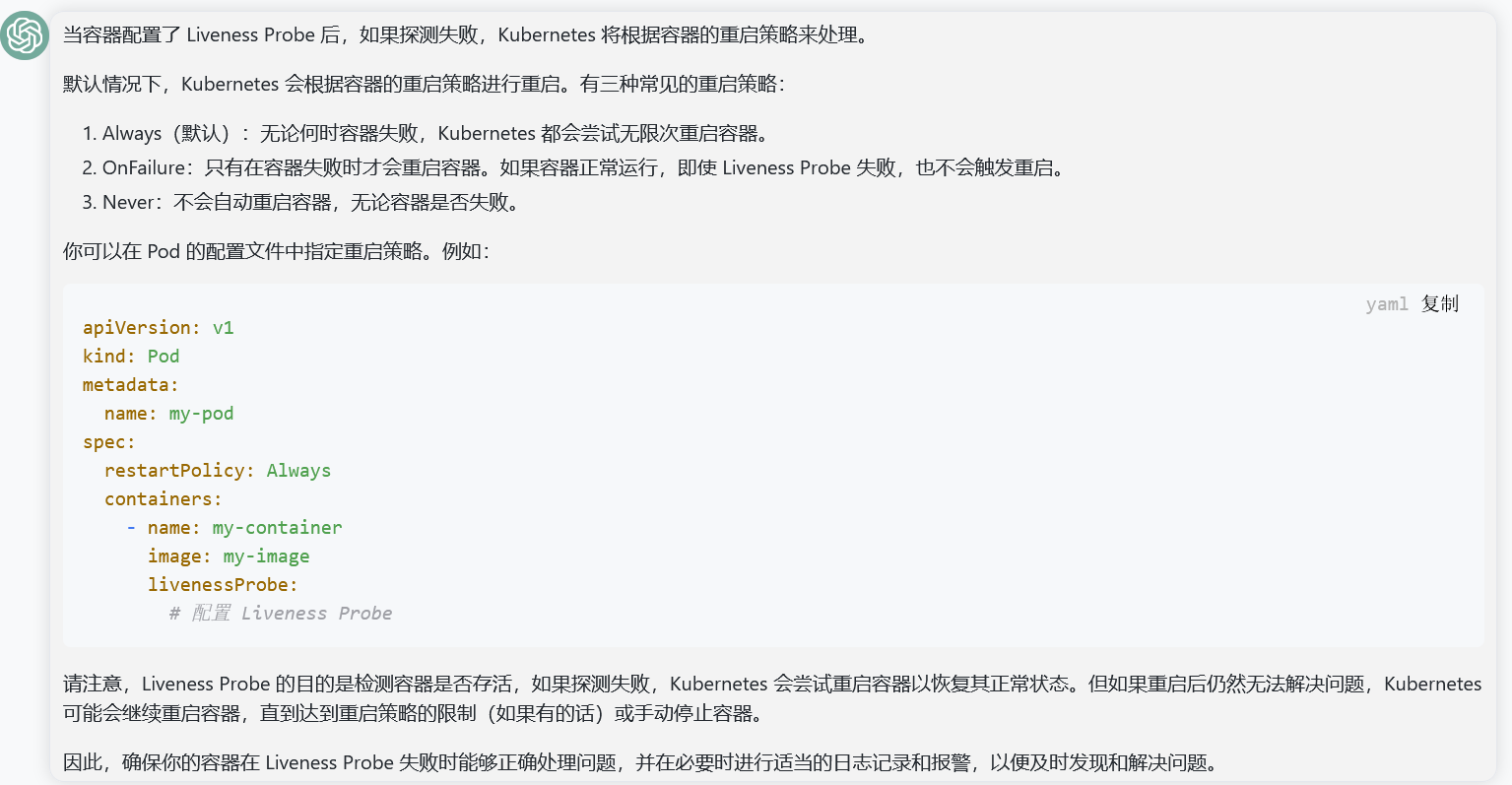
【Kubernetes 】Kubernetes 探针实战指南
Kubernetes 探针是容器健康检查的重要组件,合理配置和使用探针可以提高应用程序的可靠性。本文将介绍探针的实战指南,涵盖 Liveness Probe、Readiness Probe 的配置和高级应用,同时添加一些扩展和额外参数的说明。
1. Liveness Probe
Liveness Probe 用于确定容器是否存活。当 Liveness Probe 失败时,Kubernetes 将重启容器,以确保应用程序的健康状态。
1.1 HTTP Liveness Probe
livenessProbe: httpGet: path: /healthz port: 8080 initialDelaySeconds: 3 periodSeconds: 3 failureThreshold: 3
initialDelaySeconds 表示在容器启动后等待 3 秒后开始执行首次探测。
periodSeconds 表示每隔 3 秒进行一次探测。
failureThreshold 表示在连续 3 次探测失败后,Kubernetes 将重启容器。
Liveness Probe 的主要作用是确保容器在运行时保持活动状态,当容器处于不健康状态时,Kubernetes 会采取自动的容器重启策略。
1.2 TCP Liveness Probe
livenessProbe: tcpSocket: port: 8080 initialDelaySeconds: 3 periodSeconds: 3
对于 TCP Liveness Probe,同样可以设置 initialDelaySeconds 和 periodSeconds 参数。
1.3 Exec Liveness Probe
livenessProbe: exec: command: - cat - /tmp/healthy initialDelaySeconds: 3 periodSeconds: 3
通过 Exec Liveness Probe,执行指定的命令判断容器是否存活。在上述配置中,执行的命令是 cat /tmp/healthy。
2. Readiness Probe
Readiness Probe 用于确定容器是否准备好接收流量。当 Readiness Probe 失败时,Kubernetes 将停止向容器发送流量。
2.1 HTTP Readiness Probe
readinessProbe: httpGet: path: /ready port: 8080 initialDelaySeconds: 5 periodSeconds: 5
initialDelaySeconds 表示在容器启动后等待 5 秒后开始执行首次探测。
periodSeconds 表示每隔 5 秒进行一次探测。
2.2 TCP Readiness Probe
readinessProbe: tcpSocket: port: 8080 initialDelaySeconds: 5 periodSeconds: 5
对于 TCP Readiness Probe,同样可以设置 initialDelaySeconds 和 periodSeconds 参数。
2.3 Exec Readiness Probe
readinessProbe: exec: command: - cat - /tmp/ready initialDelaySeconds: 5 periodSeconds: 5
通过 Exec Readiness Probe,执行指定的命令判断容器是否准备好接收流量。在上述配置中,执行的命令是 cat /tmp/ready。
3. 高级应用
3.1 探针超时配置
readinessProbe: httpGet: path: /ready port: 8080 timeoutSeconds: 2
timeoutSeconds 表示探针在 2 秒内必须完成,否则将视为失败。
3.2 探针失败阈值
livenessProbe: httpGet: path: /healthz port: 8080 failureThreshold: 3
failureThreshold 表示在连续 3 次探测失败后,Kubernetes 将重启容器。
3.3 探针初始延迟随机性
livenessProbe: httpGet: path: /healthz port: 8080 initialDelaySeconds: 3 periodSeconds: 3 failureThreshold: 3 initialDelaySeconds: 5
initialDelaySeconds 在 5 秒和 8 秒之间的随机时间内开始首次探测。
4.完整案例
为了更全面地说明探针的作用,下面是一个完整的 YAML 示例,包括 Liveness Probe 和 Readiness Probe 的配置,以及容器的重启策略。此外,我添加了一些验证的注释,以便更好地理解探针的实际效果:
apiVersion: v1 kind: Pod metadata: name: myapp spec: containers: - name: myapp-container image: myapp-image ports: - containerPort: 8080 readinessProbe: httpGet: path: /ready port: 8080 initialDelaySeconds: 5 periodSeconds: 5 livenessProbe: httpGet: path: /healthz port: 8080 initialDelaySeconds: 3 periodSeconds: 3 failureThreshold: 3 restartPolicy: Always
在这个示例中:
readinessProbe 配置了一个 HTTP 探测器,用于判断容器是否准备好接收流量。该探测器在容器启动后等待 5 秒开始执行,每隔 5 秒进行一次探测。
livenessProbe 配置了一个 HTTP 探测器,用于判断容器是否存活。该探测器在容器启动后等待 3 秒开始执行,每隔 3 秒进行一次探测,如果连续 3 次探测失败,则 Kubernetes 将重启容器。
restartPolicy: Always 指定了容器的重启策略,即使容器正常退出,也会自动重启。
请确保你的应用程序在容器内实际提供了 /ready 和 /healthz 的路径,并且能够响应这些探测请求。这样,Kubernetes 才能通过这些探针来判断容器的状态,并根据需要进行重启或流量调度。
结论
通过合理配置 Liveness Probe 和 Readiness Probe,可以确保容器应用在运行时保持活动状态、可靠接收流量,并在必要时进行重启。根据应用的性能和启动时间,调整探针参数,以达到最佳的应用可维护性和可靠性。在实际应用中,根据具体需求,选择合适的探针类型和配置。
转自:https://zhuanlan.zhihu.com/p/676232290
转载请注明:jinglingshu的博客 » 探寻容器安全隔离功能实现原理