说明:虾米音乐下载地址使用凯撒阵列加密,eaglephp里集成了该加密方法的破解算法(解密算法在EaglePHP/APP/Api/XiamiController.class.php 类)。
下面的获取虾米下载地址的过程是参考网络,先讲一下我一步步的实验过程,然后再讲如何批量获取虾米的下载地址。
一、随便找一首音乐或专辑的地址:如http://www.xiami.com/song/2051566?spm=0.0.0.0.KdVec8或http://www.xiami.com/album/12372?spm=a1z1s.2635577.0.0.sdHev2。说明:http://www.xiami.com/song/2051566?spm=0.0.0.0.KdVec8是一首音乐的地址,ttp://www.xiami.com/album/12372?spm=a1z1s.2635577.0.0.sdHev2是一个专辑的地址,下面分析时是一样的,因为播放专辑时播放的是专辑中的某一首歌,因此下面点击播放时获取的地址也是一首歌的地址。
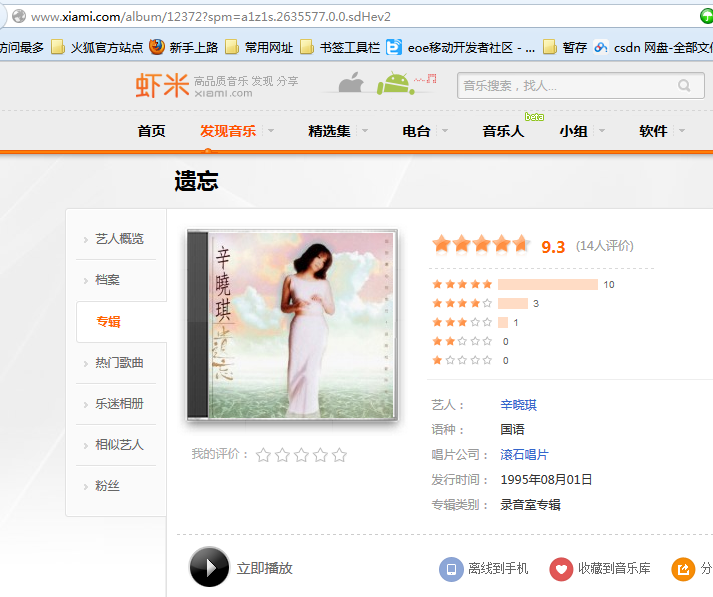
二、点击“立即播放按钮”,会弹出播放音乐的界面,但是地址栏中没有地址。按F5进行刷新,就会看到播放时的地址。

按F5刷新后,显示播放地址http://www.xiami.com/song/play?ids=/song/playlist/id/12372/type/1
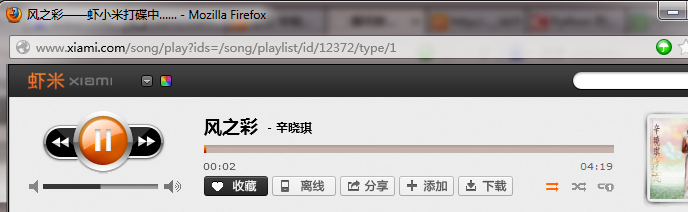
三、根据播放地址是http://www.xiami.com/song/play?ids=/song/playlist/id/12372/type/1 获取歌曲XML文档路径。即ids参数即为歌曲的XML文档路径,即http://www.xiami.com/song/playlist/id/12372/type/1
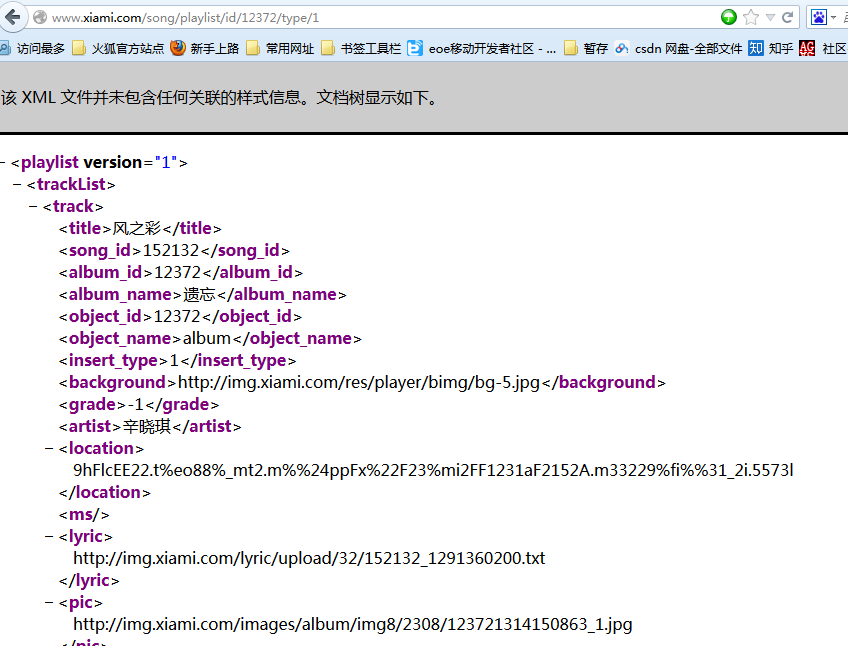
上面xml文档中的location标签里的内容即为歌曲的下载地址(当然这个地址是经过加密变换过的):9hFlcEE22.t%eo88%_mt2.m%%24ppFx%22F23%mi2FF1231aF2152A.m33229%fi%%31_2i.5573l
四、参考网上资料,虾米的下载地址经过凯撒阵列算法加密,eaglephp里集成了该加密方法的破解算法(解密算法在EaglePHP/APP/Api/XiamiController.class.php 类)。
9hFlcEE22.t%eo88%_mt2.m%%24ppFx%22F23%mi2FF1231aF2152A.m33229%fi%%31_2i.5573l

具体的破解方法是: 9表示有9行,从左到右竖着看。
竖着看连起来是http%3A%2F%2Fm1.file.xiami.com%2F3%5E8%2F23%5E8%2F12372%2F152132_42229_l.mp3。
经过urldecode后变成http://m1.file.xiami.com/3^8/23^8/12372/152132_42229_l.mp3
把^变成0,就是 http://m1.file.xiami.com/308/2308/12372/152132_42229_l.mp3
下面是自动转换的代码:
(1)PHP版(https://github.com/Flowerowl/xiami/blob/7a9185136730aecfd664b21438ca1808fb9eeb20/xiami.php)
<?php
function getLocation($location){
$loc_2 = (int)substr($location, 0, 1);
$loc_3 = substr($location, 1);
$loc_4 = floor(strlen($loc_3) / $loc_2);
$loc_5 = strlen($loc_3) % $loc_2;
$loc_6 = array();
$loc_7 = 0;
$loc_8 = '';
$loc_9 = '';
$loc_10 = '';
while ($loc_7 < $loc_5){
$loc_6[$loc_7] = substr($loc_3, ($loc_4+1)*$loc_7, $loc_4+1);
$loc_7++;
}
$loc_7 = $loc_5;
while($loc_7 < $loc_2){
$loc_6[$loc_7] = substr($loc_3, $loc_4 * ($loc_7 - $loc_5) + ($loc_4 + 1) * $loc_5, $loc_4);
$loc_7++;
}
$loc_7 = 0;
while ($loc_7 < strlen($loc_6[0])){
$loc_10 = 0;
while ($loc_10 < count($loc_6)){
$loc_8 .= isset($loc_6[$loc_10][$loc_7]) ? $loc_6[$loc_10][$loc_7] : null;
$loc_10++;
}
$loc_7++;
}
$loc_9 = str_replace('^', 0, urldecode($loc_8));
return $loc_9;
}
?>
(2)Python版(http://hi.baidu.com/cwyalpha/item/3424e2007aee8cdd72e67677)
def str2url(s):
import urllib2
#s = '9hFaF2FF%_Et%m4F4%538t2i%795E%3pF.265E85.%fnF9742Em33e162_36pA.t6661983%x%6%%74%2i2%22735'
num_loc = s.find('h')
rows = int(s[0:num_loc])
strlen = len(s) - num_loc
cols = strlen/rows
right_rows = strlen % rows
new_s = s[num_loc:]
output = ''
for i in xrange(len(new_s)):
x = i % rows
y = i / rows
p = 0
if x <= right_rows:
p = x * (cols + 1) + y
else:
p = right_rows * (cols + 1) + (x - right_rows) * cols + y
output += new_s[p]
return urllib2.unquote(output).replace('^', '0')
(3)我自己使用Python写的转换代码
import urllib2
#coding=utf8
def str2url(s):
#s = '9hFaF2FF%_Et%m4F4%538t2i%795E%3pF.265E85.%fnF9742Em33e162_36pA.t6661983%x%6%%74%2i2%22735'
num_loc = s.find('h')
rows = int(s[0:num_loc]) #行数
result = {}
s = s[num_loc:] #去除行数之后的字符串
cols = len(s)/rows
right_row = len(s)%rows #剩余的字符个数
if (right_row >0):
cols = cols+1 #如果剩余字符,则多增一列用于接受剩余的字符
for i in range(cols):
result[i] = []
print type(result[i])
#循环分配
row =0
j = 0
while row <right_row:
for i in range(cols):
result[i].append(s[j])
#result[i] = result[i].append(s[j])
j = j+1
row = row+1
while row <rows:
for i in range(cols-1):
result[i].append(s[j])
j =j+1
row = row+1
#获取结果
url = ''
for i in range(cols):
url = url+''.join(result[i])
#进行url解码和替换
url = urllib2.unquote(url).replace('^', '0')
return url
说明:我的程序使用字典来保存每一列数据,即字典的每一项为一个列表用于保存每一列。最后将所有的列表内容组成字符串即可。注意上面代码中有:#result[i] = result[i].append(s[j])这一行,将其注释掉是因为该代码是错的,因为result[i]是一个列表,列表是一个可变类型直接用append添加即可改变字典中该列表的值。同时,由于由于append()函数无返回值,如果将append()函数的结果赋给result[i]将导致result[i]变为空类型,最终导致报错:AttributeError: ‘NoneType’ object has no attribute ‘append’。
——————————————————————————————————————————–
上面讲的是一首歌曲详细的获取下载地址的过程,下载讲下使用代码批量获取下载地址的方法:
1、每一首歌和专辑都有一个地址,如上面分析时用的http://www.xiami.com/album/12372?spm=a1z1s.2635577.0.0.sdHev2,其中查询中的数字即为该专辑的ID值,不同的ID对应的不同的专辑。歌曲的地址是:http://www.xiami.com/song/2051566?spm=0.0.0.0.KdVec8,同样歌曲的ID为查询部分的数字,即2051566,不同的ID对应的不同的歌曲。因此,批量时只要逐渐递增该参数即可。歌曲的ID是一个7位的数字,不同的数字代表不同的歌曲。

(2)获取了一个歌曲的ID后,访问http://www.xiami.com/song/playlist/id/{ID值}/type/1即可获取XML文档,如http://www.xiami.com/song/playlist/id/0000001/type/1

其中location的标签中的值即为加密后的下载地址,根据上面程序进行解密即可。
总结:下载指定歌曲程序的流程是:根据歌曲url获取歌曲ID,根据歌曲ID访问XML文档,解析文档获取加密后的下载地址,然后解密下载地址即可。
参考文章:
1、http://hi.baidu.com/maojianlw/item/ad7ccb3e49bbb80acfb9fe4a
2、http://hi.baidu.com/cwyalpha/item/3424e2007aee8cdd72e67677
3、https://github.com/Flowerowl/xiami/blob/7a9185136730aecfd664b21438ca1808fb9eeb20/xiami.php
4、http://www.douban.com/group/topic/21801800/
5、http://blog.csdn.net/facevoid/article/details/5338048
转载请注明:jinglingshu的博客 » 虾米音乐下载地址破解算法