https://www.datacon.org.cn/competition/competitions/91/introduction
该项目基于datacon比赛2024年漏洞分析赛道冠军战队0817iotg的完整解题框架,集成了一个基于大模型的自动化漏洞分析系统,内容包括情报提取和漏洞分析两部分内容的可执行docker压缩包以及相关功能说明
一、情报提取
1.1问题描述
在进行漏洞挖掘工作时,对特定目标的历史漏洞挖掘经验的学习是至关重要的一步。然而,传统的搜索引擎在面对海量数据时往往显得效率低下,难以快速有效地获取所需的关键信息。近年来,随着人工智能大模型技术的发展及其在自然语言处理方面的显著进步,利用大模型从海量漏洞分析文章中提取关键知识已经成为一种可行的方法。 本挑战要求选手利用大模型技术,对漏洞分析文章进行高效梳理,从中提取出有价值的摘要信息,任务包括但不限于:文献整理、文本预处理、关键信息提取、摘要生成、结果验证等。
1.2核心思路
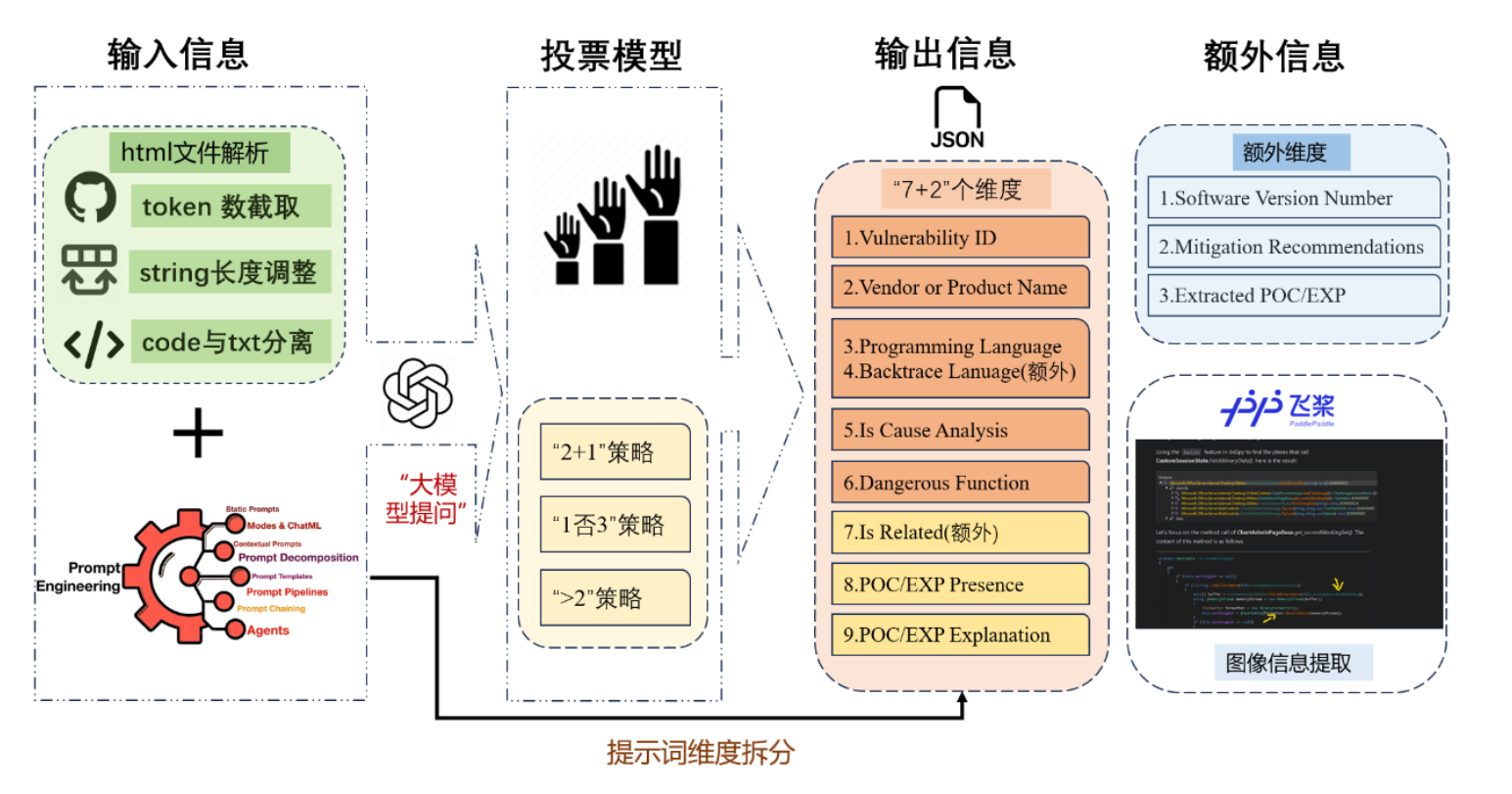
- 相关内容的源码位于task1_source_code目录下,主功能文件为test.py, test_examples目录下为该任务的部分测试数据集
- 使用BeautifulSoup4解析html文件,去除图片等无用信息。
- 运用提示工程方法生成精细化提示,拆分输出维度,使用两次大模型调用分别判定不同输出维度
- 运用投票模型检查结果,减少大模型输出内容的不确定性,并且去除不合理结果
- 扩展框架功能与识别范围,使其能够识别版本、修复建议;提取POC/EXP代码;以及支持图片内容识别
- 1、能够调用大模型api对漏洞文章中的多维度信息进行自动的批量化提取,提取的信息维度包括文件名、漏洞编号、厂商或产品名、编程语言、是否有漏洞成因分析、危险函数名、是否有 POC/EXP、是否有 POC/EXP 解释
- 2、在功能1的基础上进一步对文章中的潜在POC/EXP进行判断并提取,在task1_source_code目录下的appendix.py文件中实现了相关功能
- 3、能够对漏洞文章中的图片信息进行识别并提取,在task1_source_code目录下的pic_expand.py文件中实现了相关功能
漏洞挖掘是网络安全工作中不可或缺的一环,但传统的审计方法耗时耗力,且静态分析技术存在一定的局限性。随着人工智能技术特别是大模型的发展,通过对代码中的语义进行深度分析,实现更为精准的漏洞挖掘已经成为可能。这种新型的技术手段不仅提高了漏洞检测的准确性,还极大地提升了工作效率。 本题要求选手自行编写程序,并结合大模型技术自动化识别出漏洞样例中存在的安全隐患。具体任务包括:知识提取、代码分析、漏洞识别、误报消除等。通过本次比赛,参赛者不仅能够积累漏洞模式增强自身的漏洞挖掘能力,还能深入了解大模型在漏洞检测领域的应用前景。这不仅有助于提高个人的网络安全技术水平,也为未来网络安全工具的研发提供了新的思路。
2.2核心思路
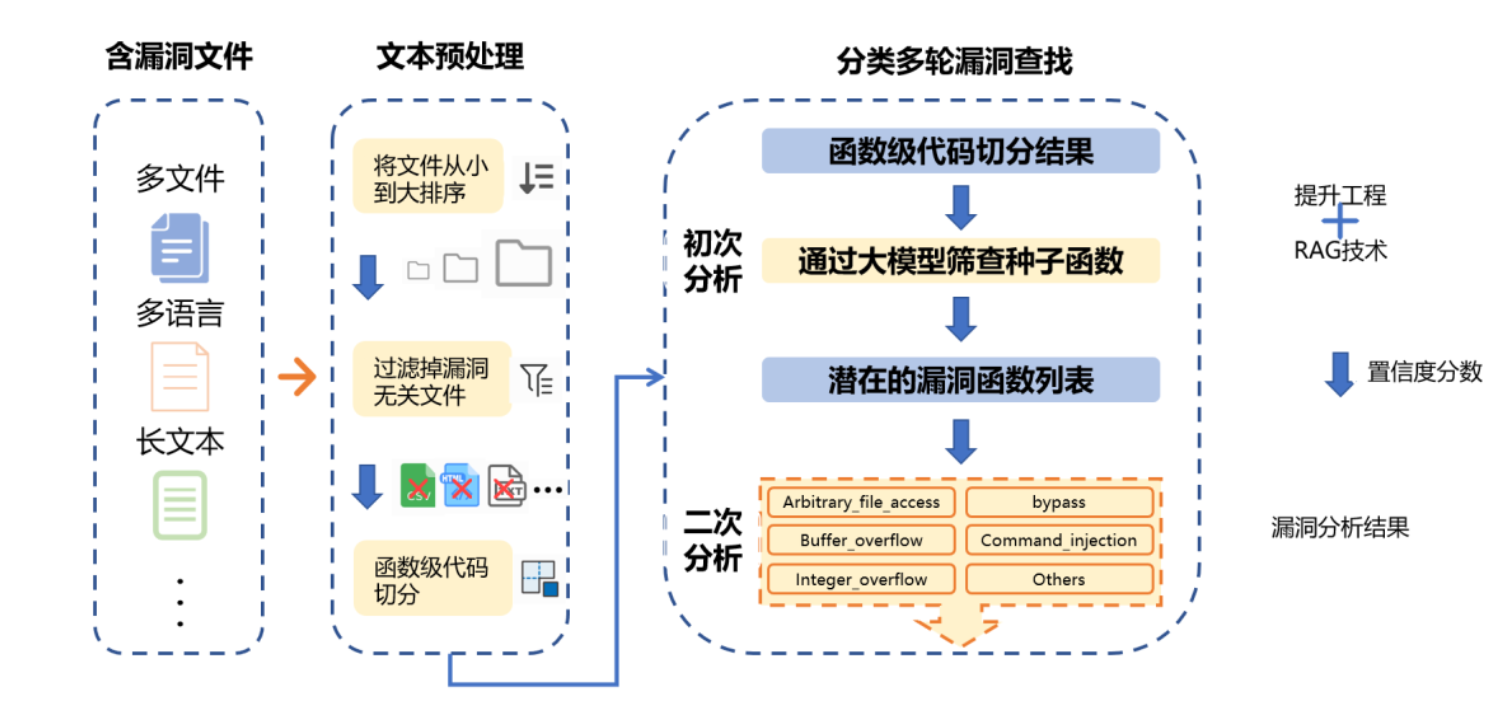
- 相关内容的源码位于task2_source_code目录下,存在两个代码功能版本,first_version目录下为基础版本,其实现的功能为仅通过设计提示词分析题目所提供的7类漏洞;final_version目录下的最终版本,具体功能实现为,在设计提示词的过程中额外加入了一部分已知漏洞信息作为规则,从而提高大模型分析的准确率
- 根据文件总大小对待分析文件进行排序
- 过滤无关文件类型,然后根据编程语言进行函数切分
- 运用多种方法分类进行漏洞查找
- 针对代码量过大的工程,使用基于提示工程的初步筛查提取可能包含漏洞的种子函数
- 根据函数切分结果与初筛结果提取种子函数内容,根据不同漏洞类型,调用不同子模块进行二次筛查
- 针对漏洞模式较为简单的漏洞类型,使用提示工程进行漏洞筛查
- 针对漏洞样例种类丰富的漏洞类型,使用RAG技术进行漏洞筛查
- 针对其他漏洞类型,结合两种思路,根据测试效果择优选择
- 1、能够针对复杂情况实现函数级别的切分,能够针对多文件、长代码(上万行)、多语言类型的原始分析样本进行切分处理,并最终通过排序以及多轮提示,将涉及漏洞的代码内容完整地提供给大模型进行分析。
- 2、能够针对多种不同的漏洞类型(race conditon、sql注入、double-fetch等)进行初筛与分类,并在此基础上选择特定的分析提示词,实现各类漏洞自动化的分析
- 3、针对已指定的漏洞类型(buff_overflow、command_injection等),通过较为完备的提示词以及置信度分析方法,利用大模型分析出最有可能的漏洞函数
转自:https://github.com/123f321/datacon24_vuln_wp?tab=readme-ov-file
转载请注明:jinglingshu的博客 » datacon24_vuln_wp