https://code.google.com/p/python-spidermonkey/
——————————————————————————————————-
最近,想从中国天气网上抓取数据,其中的网页上的实时天气是使用javascript生成的,用简单的标签解析不到。原因是,那个标签压根就没再网页当中。
所以,google了下python怎么区解析动态网页,下面文章对我很有帮助。
转载记录:Python在Web Page抓取、JS解析方面的介绍
因为我只希望在mac下解析,所以我并没有使用扩平台的库。在使用spidermonkey后,发现它还是很全面,比如 document.write就无法执行(如果我的认识有错误,请指出,谢谢)。我将目光落在了pywebkitgtk上,可惜安装不成功,逼迫我放弃了 (我有考虑过使用pyv8,但是还是放弃了)。
在经历了失败后,我还是从homebrew这个神器上发现了希望。它可以帮你安装pyqt,可能知道它是一个python的界面库,但是它同样拥有网络模块(webkit),当然也可以使用它来解析网页。
我将分析一下我解析动态网页的过程,此过程实现多于原理学习:
第一步:解析静态网页标签

1 <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> 2 <html> 3 <head> 4 <title>javascript测试网页</title> 5 </head> 6 <body> 7 <script type="text/javascript" src="./5757.js"> 8 </script> 9 </body> 10 </html>
上面是测试用的html代码,我将解析它的title标签,很简单,呵呵~
1 #! /usr/bin/env python 2 3 from htmlentitydefs import entitydefs 4 from HTMLParser import HTMLParser 5 import sys,urllib2 6 7 class DataParser(HTMLParser): 8 def __init__(self): 9 self.title = None 10 self.isTag = 0 11 HTMLParser.__init__(self) 12 13 def handle_starttag(self,tag,attrs): 14 if tag == 'title': 15 self.isTag = 1 16 17 18 def handle_data(self,data): 19 if self.isTag: 20 self.title = data 21 22 def handle_endtag(self,tag): 23 if tag == 'title': 24 self.isTag = 0 25 def getTitle(self): 26 return self.title 27 28 url = 'file:///Users/myName/Desktop/pyqt/2.html' 29 #''中内容用浏览器打开,直接复制地址栏的内容即可 30 req = urllib2.Request(url) 31 fd = urllib2.urlopen(req) 32 parser = DataParser() 33 parser.feed(fd.read()) 34 print "Title is:",parser.getTitle()
结果是:

第二步 安装库
1.我假设你已经安装了python。
2.在开始解析动态网页之前,先要安装pyqt,让brew去替你安装,能帮你节省很多精力。。。
![]()
了解更多homebrew,请访问官网:homebrew官网
3.说明:本来pyqt是一个GUI库,但它包含了网络模块webkit,这个将用于解析动态网页。
第三步 解析javascript动态标签
1.有很多标签是动态添加到html网页中的,所以有时候用python去执行javascript可能不能达到条件,比如动态添加的标签,所以获得执行后dom树是一种比较通用的方法。(可能理解不正确,如果不对,请指正)。
2.来写一个给上面html文件外部调用的js文件。
1 alert("这是被调用的语句。")
2 var o = document.body;
3 function createDIV(text)
4 {
5 var div = document.createElement("div");
6 div.innerHTML = text;
7 o.appendChild(div);
8 }
9 createDIV("15");
3.此时,双击2.html,看到的效果是:
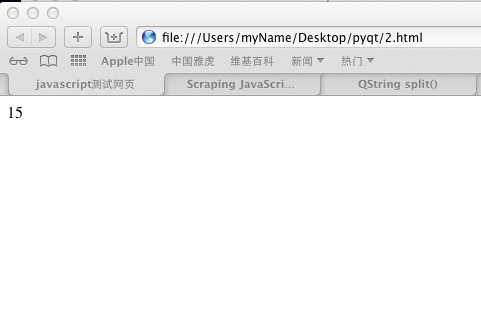
只有一个15,这就是我们要解析的数据,现在再来看下浏览器显示的源码:
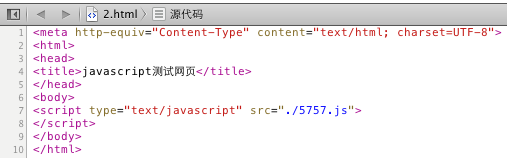
是不是没有div标签,所以现在解析,不可能获取到的,应为div是5757.js添加上去的(js名字乱取的)~
下面就开始解析,我的问题解决受益于这篇文章,希望大家也能看看:Scraping JavaScript webpages with webkit
我们要利用webkit获取执行后的dom树:
1 #! /usr/bin/env python
2
3 import sys,urllib2
4 from HTMLParser import HTMLParser
5 from PyQt4.QtCore import *
6 from PyQt4.QtGui import *
7 from PyQt4.QtWebKit import *
8
9 class Render(QWebPage):
10 def __init__(self, url):
11 self.app = QApplication(sys.argv)
12 QWebPage.__init__(self)
13 self.loadFinished.connect(self._loadFinished)
14 self.mainFrame().load(QUrl(url))
15 self.app.exec_()
16
17 def _loadFinished(self, result):
18 self.frame = self.mainFrame()
19 self.app.quit()
20
21 url = './2.html'
22 r = Render(url)
23 html = r.frame.toHtml()
24 print html.toUtf8()
25
26 # 将执行后的代码写入文件中
27 f = open('./test.txt','w')
28 f.write(html.toUtf8())
29 f.close()
我显示print出来结果,后又将结果写入test.txt文件。现在来看看test.txt中有什么(不要双击,否则只有一个15,用你的文本编辑器去查看,比如:sublime text2):
1 <html><head><meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> 2 3 4 <title>javascript测试网页</title> 5 </head> 6 <body> 7 <script type="text/javascript" src="./5757.js"> 8 </script><div>15</div> 9 10 </body></html>
看起来像html代码,但是得到了我想要的东西,注意第八行,出现了div标签~。
最后一步,获取那个15。
停一下,想一下我们怎么去获取:
1 html = r.frame.toHtml()
得到一个QString对象,它不属于python标准库。我想在我熟悉pyqt的始末之前,将它转换成python对象让我感到更加自在一点。我们可以像解析静态网页般区解析它,关键在于这一句:
1 parser.feed(fd.read())
当然既然能将它写入到本地文件,打开文件->解析文件->获取数据也是可以的,但我想没人想那么麻烦。
查阅一下python的文档:
1 HTMLParser.feed(data) 2 3 Feed some text to the parser. It is processed insofar as it consists of complete elements; incomplete data is buffered until more data is fed or close() is called.data can be either unicode or str, but passing unicode is advised.
发现只要将unicode或str传入,我们就能顺利解析,也许稍微改动下代码即可:
1 ! /usr/bin/env python
2
3
4 import sys,urllib2
5 from HTMLParser import HTMLParser
6 from PyQt4.QtCore import *
7 from PyQt4.QtGui import *
8 from PyQt4.QtWebKit import *
9
10 class DataParser(HTMLParser):
11 def __init__(self):
12 self.div = None
13 self.isTag = 0
14 HTMLParser.__init__(self)
15
16 def handle_starttag(self,tag,attrs):
17 if tag == 'div':
18 self.isTag = 1
19
20
21 def handle_data(self,data):
22 if self.isTag:
23 self.title = data
24
25 def handle_endtag(self,tag):
26 if tag == 'div':
27 self.isTag = 0
28 def getDiv(self):
29 return self.title
30
31
32 class Render(QWebPage):
33 def __init__(self, url):
34 self.app = QApplication(sys.argv)
35 QWebPage.__init__(self)
36 self.loadFinished.connect(self._loadFinished)
37 self.mainFrame().load(QUrl(url))
38 self.app.exec_()
39
40 def _loadFinished(self, result):
41 self.frame = self.mainFrame()
42 self.app.quit()
43
44 url = './2.html'
45 r = Render(url)
46 html = r.frame.toHtml()
47 #print html.toUtf8()
48
49 parser = DataParser()
50 parser.feed(str(html.toUtf8()))
51 print "javascript is",parser.getDiv()
52
53
54 #f = open('./test.txt','w')
55 #f.write(html.toUtf8())
56 #f.close()
代码做了简单的合并,就将数据解析出来了,运行结果如下:
![]()
呵呵,虽然只有3个词,但的确成功解析了动态标签,呵呵~
第四步 想说的话
文章的实现多于原理,希望对阅读文章的人提供一定的帮助。如有不对的地方也请指正。
当然,要将文章的东西直接运用到实际是不现实的,但希望这是一个好的起点。
转自:http://www.cnblogs.com/asmblog/archive/2013/05/07/3063809.html
转载记录:Python在Web Page抓取、JS解析方面的介绍
转自:http://codinglife.sinaapp.com/?p=189
由于目前的Web开发中AJAX、Javascript、CSS的大量使用,一些网站上的重要数据是由Ajax或Javascript动态生成的,并不能直接通过解析html页面内容就能获得(例如采用mechanize、lxml、Beautiful Soup )。要实现对这些页面数据的爬取,爬虫必须支持Javacript、DOM、HTML解析等一些浏览器html、javascript引擎的基本功能。
正如Web Browser Programming in Python总结的,在python程序中,有如下一些项目提供能类似功能:
其中Pyv8主要是Google Chrome V8 Javascript引擎的Python封装,侧重在Javacript操作上,并不是完整的Web Browser 引擎,而诸如PythonWebKit、Python-Spidermonkey、PyWebKitGtk等几个主要在Linux平台上比较方便,而HulaHop、Pamie处理MS IE 。因此从跨平台、跨浏览器、易用性等角度考虑,以上方案并不是最好的。
Selenium、Windmill 原本主要用于Web自动化测试上,对跨操作系统、跨浏览器有较好的支持。其对Javacript、DOM等操作的支持主要依赖操作系统本地的浏览器引擎来实现,因此爬虫所必须的大部分功能,Selenium、Windmill 都有较好的支持。在性能要求不高的情况下,可以考虑采用Selenium、Windmill的方案,从评价来看,Windmill比Selenium功能更加全面。
争取其他语言一些类似的软件还有:
- Lobo Browser(Java Browser)
- Rhino (Java Javascript Engine)
- Htmlunit、TestNG (Java Testing Framework)
- Watir (Ruby)
1、应用场景
关于Selenium的详细说明,可以参考其文档, 这里使用Python+Selenium Remote Control (RC)+Firefox 来实现如下几个典型的功能:
1)、 Screen Scraping,也即由程序自动将访问网页在浏览器内显示的图像保存为图片,类似那些digg站点的网页缩略图。Screen Scraping有分成两种:只Scraping当前浏览器页面可视区域网页的图片(例如google.com首页),Scraping当前浏览器完整页 面的图片(页面有滚动,例如www.sina.com.cn的首页有多屏,需要完整保存下来)
2)、获取Javascript脚本生成的内容
例如要用程序自动爬取并下载百度新歌TOP100 的所有新歌,以下载萧亚轩的《抱紧你》为例,大致步骤可以如下:
a)、进入百度新歌TOP100http://list.mp3.baidu.com/top/top100.html,通过正则表达式匹配<a target=”_blank” href=”http://mp3.baidu.com/m?(.*)” class=”search”></a> 或采用mechanize、Beautiful Soup之类的htmlparser解析页面获得每一首歌后面的查询地址
b)、在查询结果页面,获得第一条结果的地址<a href=”http://202.108.23.172(.*)” title=”(.*)</a>,进入mp3的实际下载地址
c)、在歌曲实际下载页面,解析html页面内容,会发现mp3的实际现在地址为空
<a id="urla" href="" onmousedown="sd(event,0)" target="_blank"></a>
实际的下载地址是由javascript脚本设置的:
var encurl = "…", newurl = "";
var urln_obj = G("urln"), urla_obj = G("urla");
newurl = decode(encurl);
urln_obj.href = urla_obj.href = song_1287289709 = newurl;
其中函数G(str)为:
function G(str){
return document.getElementById(str);
};
因此直接解析页面并不能获得下载地址,必须通过python调用浏览器引擎来解析javascript代码后获得对应的下载地址。
2、Selenium RC基础
Selenium RC的运行机制及架构在官方文档中有详细说明。
Selenium RC主要包括两部分:Selenium Server、Client Libraries,其中:
- The Selenium Server which launches and kills browsers, interprets and runs the Selenese commands passed from the test program, and acts as an HTTP proxy, intercepting and verifying HTTP messages passed between the browser and the AUT.
Selenium Server 对应Selenium RC 开发包中的selenium-server-xx目录,其中
xx对应相应的版本
- Client libraries which provide the interface between each programming language and the Selenium-RC Server.
Selenium RC提供了包括java、python、ruby、perl、.net、php等语言的client driver,分别如下:
selenium-dotnet-client-driver-xx
selenium-java-client-driver-xx
selenium-perl-client-driver-xx
selenium-php-client-driver-xx
selenium-python-client-driver-xx
selenium-ruby-client-driver-xx

Python 等语言通过调用client driver来发出浏览器操作指令(例如打开制定url),由client driver把指令传递给Selenium Server解析。Selenium Server负责接收、解析、执行客户端执行的Selenium 指令,转换成各种浏览器的命令,然后调用相应的浏览器API来完成实际的浏览器操作。
Selenium Server实际充当了客户端程序与浏览器间http proxy。
3、例子:
1)、下载Selenium RC http://seleniumhq.org/download/,测试使用的selenium-remote-control-1.0.3.zip
2)、解压后selenium-remote-control-1.0.3.zip
3)、运行Selenium Server
cd selenium-remote-control-1.0.3\selenium-server-1.0.3
java -jar selenium-server.jar
Selenium Server缺省监听端口为4444,在org.openqa.selenium.server.RemoteControlConfiguration中设定
4)、测试代码
#coding=gbk
from selenium import selenium
def selenium_init(browser,url,para):
sel = selenium('localhost', 4444, browser, url)
sel.start()
sel.open(para)
sel.set_timeout(60000)
sel.window_focus()
sel.window_maximize()
return sel
def selenium_capture_screenshot(sel):
sel.capture_screenshot("d:\\singlescreen.png")
def selenium_get_value(sel):
innertext=sel.get_eval("this.browserbot.getCurrentWindow().document.getElementById('urla').innerHTML")
url=sel.get_eval("this.browserbot.getCurrentWindow().document.getElementById('urla').href")
print("The innerHTML is :"+innertext+"\n")
print("The url is :"+url+"\n")
def selenium_capture_entire_page_screenshot(sel):
sel.capture_entire_page_screenshot("d:\\entirepage.png", "background=#CCFFDD")
if __name__ =="__main__" :
sel1=selenium_init('*firefox3','http://202.108.23.172','/m?word=mp3,http://www.slyizu.com/mymusic/VnV5WXtqXHxiV3ZrWnpnXXdrWHhrW3h9VnRkWXZtXHp1V3loWnlrXXZlMw$$.mp3,,[%B1%A7%BD%F4%C4%E3+%CF%F4%D1%C7%D0%F9]&ct=134217728&tn=baidusg,%B1%A7%BD%F4%C4%E3%20%20&si=%B1%A7%BD%F4%C4%E3;;%CF%F4%D1%C7%D0%F9;;0;;0&lm=16777216&sgid=1')
selenium_get_value(sel1)
selenium_capture_screenshot(sel1)
sel1.stop()
sel2=selenium_init('*firefox3','http://www.sina.com.cn','/')
selenium_capture_entire_page_screenshot(sel2)
sel2.stop()
几点注意事项:
1)、 在selenium-remote-control-1.0.3/selenium-python-client-driver-1.0.1/doc/selenium.selenium-class.html 中对Selenium支持的各种命令的说明,值得花点时间看看
2)、在__init__(self, host, port, browserStartCommand, browserURL) 中,browserStartCommand为使用的浏览器,目前Selenium支持的浏览器对应参数如下:
*firefox
*mock
*firefoxproxy
*pifirefox
*chrome
*iexploreproxy
*iexplore
*firefox3
*safariproxy
*googlechrome
*konqueror
*firefox2
*safari
*piiexplore
*firefoxchrome
*opera
*iehta
*custom
3)、capture_entire_page_screenshot目前只支持firefox、IE
使用firefox时候使用capture_entire_page_screenshot比较简单,不需要特别设置,Selenium会自动处理。因此如果使用capture_entire_page_screenshot推荐使用firefox。
IE必须运行在非HTA(non-HTA)模式下(browserStartCommand值为:*iexploreproxy ),并且需要安装http://snapsie.sourceforge.net/ 工具包,具体可以参考这篇文章:Using captureEntirePageScreenshot with Selenium
In the previous post I covered how to tackle JavaScript based websites with Chickenfoot. Chickenfoot is great but not perfect because it:
- requires me to program in JavaScript rather than my beloved Python (with all its great libraries)
- is slow because have to wait for FireFox to render the entire webpage
- is somewhat buggy and has a small user/developer community, mostly at MIT
An alternative solution that addresses all these points is webkit, the open source browser engine used most famously in Apple’s Safari browser. Webkit has now been ported to the Qt framework and can be used through its Python bindings.
Here is a simple class that renders a webpage (including executing any JavaScript) and then saves the final HTML to a file:
import sys
from PyQt4.QtGui import *
from PyQt4.QtCore import *
from PyQt4.QtWebKit import *
class Render(QWebPage):
def __init__(self, url):
self.app = QApplication(sys.argv)
QWebPage.__init__(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec_()
def _loadFinished(self, result):
self.frame = self.mainFrame()
self.app.quit()
url = 'http://webscraping.com'
r = Render(url)
html = r.frame.toHtml()
I can then analyze this resulting HTML with my standard Python tools like the webscraping module.
-

Mike Thanks for this great tutorial. Very concise and useful.
I have one question: how can one ensure that AJAX content has loaded? I find that _loadFinished is triggered before AJAX content has finished loading.
-

Richard Mod yes certainly – you could wait for redirection and then get the current URL:
http://www.pyside.org/docs/pys… -

Jimmy Thanks for the great tutorial. How can you use PyQt4.QtWebKit to fill out a form and submit it? I am trying to replicate the basic functions from Mechanize.
-
Richard Mod Jimmy hi Jimmy, glad it was useful. This later post shows how to submit a form:
http://sitescraper.net/blog/Au…
-
-

HaThanh Thank you so much! This is simply great!
-

Maddy Hi! Many thanks for this helpful post! I’m trying to understand how Parse class works but O’m not sure what does self.loadFinished.connect(self._loadFinished)line do? Couldnt’t find connect method in the documentation. Thanks.
-
Richard Mod Maddy Glad this was helpful.
The loadFinished signal will be called by QWebPage when the URL finishes downloading, and then this is connected to an internal method to process the event.
Here is the relevant documentation: http://doc.qt.digia.com/4.7/qw…
-
-

acer It returns html head /head body /body /html
Should it return whole page? -

Pratik I wanted to scrap blackberry app world and was looking for ways to do it because they use jquery function calls to a web service to load new application on same page. I came across your blog and found it useful. I am not familiar with python but I use Java for other web scraping I did before for android and windows apps. But for blackberry that method wont work. So just wanted some help on how I can proceed with this ?
I am a beginner in web scraping field so any help would be great.-
Richard Mod Pratik Glad this was useful.
Try Firebug or similar to check what AJAX calls are made to that web service and then have your script call those URLs directly.
Or if JavaScript interaction is too complex then use a browser renderer like webkit. If using Java then selenium / webdriver may be useful.-
Pratik Richard Thank You !
I tried Firebug before but was complex couldn’t figure out much and I didn’t found any links they were calling.
As you suggested I tried Selenium a bit and it looks good and I can export test cases to Java too in it. So will explore more on it. Thanks for suggestion.
Might ask you again if any help needed !!
-
-
-

John This was a huge help. Thanks!
-

Kenji Great tutorial!
Is there a way to quit QWebPage after calling Render so that it restarts|reloads when it is called again?
I tried the version for multiple urls but it doesn’t work for me. And in this version all works fine for the first url but the next few don’t work anymore (get the html without the javascript loaded).-
-
Kenji Richard My specs:
Arch Linux (
Linux 3.5.3-2-ck #1 SMP PREEMPT 2012 x86_64 GNU/Linux
pyqt 4.9.4-2
Python 2.7.3I am not trying to open the same website, but different webpages. I don’t know why it would be caching anything.
-
-
-

Ajak Saksow Thanks a lot. Am I the only one having segfaults when running the script a second time? (I’ve just added a function that writes “html” in a given file) Thank you.
-
Ajak Saksow Ajak Saksow This script works for me only the first time, then it doesn’t generate correctly the html file. Any clue? Is it from Qt?
-
Richard Mod Ajak Saksow Strange. Sorry I have no idea. What OS are you using? And are there any error messages? Qt seg faults happen at the C++ level so are often a black box.
-
-
-

zombieseagull Hello, I’m trying to track a Javascript redirection made by a given url. Basically I want to let PyQt do the redirection and get the destination url after the redirection happens. I read quite a lot of documentation and tried other tools like Windmill or HtmlUnit but I didn’t find a way to do so. Is there a way to extract the destination url with PyQt?
-

Richard yes you are only allowed to define a single QApplication instance. Here is a modified example for crawling multiple URL’s:
http://blog.sitescraper.net/20… -

Unknown i want to load a list of URLs and scrape some value in each page.
But using the example above and some modification like this:
urllist = [‘https://market.android.com/det…]
p = re.compile(r’num\d”>(\d+)<‘)
for detailurl in urllist:
r = Render(QUrl(detailurl))
html = r.frame.toHtml()
matched = p.findall(html)
print matchedthen i got the error:A QApplication instance already exists.
how can i reload the frame using new URL and get the content? thx. -
Richard yes webkit could manage this – you can catch the finished() signal to check AJAX responses.
-

jeremiah Hello. I need help creating a web scraping application to capture information from a dynamic web page. The page employs periodic XMLHttpRequest requests, once per second and the objective is to capture and log all responses. The server sets cookies both through http and javascript methods and requires these cookies in the request headers. It appears that a Webkit hack could accomplish this. Is anyone able to help with this?
-
Richard yes, you can track downloading progress via the loadProgress(int) signal: http://www.riverbankcomputing….
-

winograd Hi, is there a way to track the progress of page loading, something like getting the amount of data loaded from url?
Thanks!
-

Anonymous I would like to call a method multiple times, each time with a different URL. I see that the load and app.exec_ can be moved to a loadURL method, but I don’t see how to support multiple calls… please enlighten,. being stuck on it for a while now.
-
Richard Currently the loading code is in the constructor so the class is not efficient for loading multiple URL’s. You should refactor and put the loading code in a method.
-
Anonymous Is it possible to load multiple URLs without touching the Render class.
-

Aurelien Thanks a lot for these useful information, it helped me a lot.
However when I try to connect to this website, https[://]www[dot]securitygarden[dot]com, I fail to establish a connection. I’m one of the contributor of this project and i would like to test the efficiency of content obtained with PySide/PyQt.
I don’t know the origin of the problem, because I can connect to that URL with urllib2. If you have an idea thanks in advance, and thanks again for the articles on this blog that I find useful and interesting.
-
Richard Seems that you installed pyside manually and now you have a version dependency problem. Can you install a more recent version of libpng?
Or if you use package management to install the dependencies will be taken care of.This is what I used on Ubuntu to install PyQt:
sudo apt-get install python-qt4
-

Thomas This is fantastic! It actually took some work to get PySide installed, but now i’m having this problem:
from PySide.QtGui import *
Traceback (most recent call last):
File “”, line 1, in
ImportError: dlopen(/opt/local/Library/Frameworks/Python.framework/Versions/2.6/lib/python2.6/site-packages/PySide/QtGui.so, 2): Library not loaded: /opt/local/lib/libpng12.0.dylib
Referenced from: /opt/local/lib/libQtGui.4.dylib
Reason: Incompatible library version: libQtGui.4.dylib requires version 45.0.0 or later, but libpng12.0.dylib provides version 44.0.0Any ideas?
-
Richard Don’t worry about the particular javascript used. Instead analyze the download request this triggers and then replicate this yourself.
-

Jen Thanks! I got the URL of the ‘download’ button using firebug, but it consists of a (dynamically generated based on which checkboxes are selected) javascript call to a regularly updated database, rather than a direct file path:
https://www.quantcast.com/down…
Do you have any ideas on how to replicate the download request using that? Thanks so much; I really appreciate your time 🙂
-
Jen Great, thanks!!
-
Richard Yes could do this with webkit, but probably easier to just replicate the download request. There are firefox extensions that can help you with this, such as firebug.
-
Jen Hi Richard,
I am quite new to all of this so pardon me if my questions are fundamental. I am trying to scrape information from a webpage that is practically entirely encoded in Javascript, and listed in a dynamic table on multiple pages. The site also happens to have a ‘Download’ button that conveniently puts all the data into a csv file. I don’t know whether it would be easier to automate the clicking of this button, or the scraping of the code itself–if the former, is there a way to do this with WebKit or something else that doesn’t require too many downloads? If the latter, how can I view the saved HTML from the rendered webpage? Any insight would be appreciated. Thanks! -
Richard the _loadFinished signal won’t be called until the page and it’s resources are loaded. If you need additional time you could call something like this before exiting the app:
def wait(self, secs=10):
deadline = time.time() + secs
while time.time() < deadline:
time.sleep(0.1)
self.app.processEvents() -

Jabba Laci Thanks, I was looking for something like this. However, if the load time of the page requires much time (for instance 10 seconds in a browser), how to get that? This script terminates quickly and doesn’t fetch everything. I guess it can be done with QTimer but I don’t know how to integrate a timeout limit.
-
Richard I see a followup to your login question was made here:
http://stackoverflow.com/quest… -
Anonymous Hi Richard, you example code is really what i have been looking for online for so long. I am new to QtWebKit and would like to ask a few question regarding the example code.
Q1) I replaced the url link in your example code with:
r = Render(“http://quote.morningstar.com/s…“)Code seems working, but I am getting error message as following:
QSslSocket: cannot call unresolved function SSLv3_client_method
QSslSocket: cannot call unresolved function SSL_CTX_new
QSslSocket: cannot call unresolved function SSL_library_init
QSslSocket: cannot call unresolved function ERR_get_errorQ2) I added a line in the end as “print html”. I am getting following errors:
Traceback (most recent call last):
File “D:\MyStuffs\Hobbies\AlienProjects\Stocks\Scrape\webK.py“, line 25, in
print html
UnicodeEncodeError: ‘ascii’ codec can’t encode character u’\u2013′ in position 585: ordinal not in range(128)Is html an object or a reference to the captured web page text? How do I print page out?
Thanks,
— Wei
-
Richard I prefer solutions that are cross platform with minimal dependencies, so easier to deploy to clients.
Isn’t xdotool only for X11? -

kristopolous You can also interface xdotool for mouse events.
-
Richard webkit supports cookies like a normal browser, so you could make it submit the login form before accessing the content.
-
Anonymous Would it be possible to add authentication? This is almost exactly what I need, but the page I want to access is on our company intranet and requires a login to view.
Thanks for the example! It’s a huge help.
–Mike
-
Richard Yes, you can simulate mouse events through JavaScript:
e.evaluateJavaScript(“var evObj = document.createEvent(‘MouseEvents’); evObj.initEvent(‘click’, true, true); this.dispatchEvent(evObj);”)