参考文章:
1、《浏览器urlencode策略差异导致XSS风险》(需翻墙)—–余弦
2、《浏览器差异带来的XSS风险1》http://evilcos.me/?p=24
本文分两部分介绍不同浏览器urlencode的差异:对特殊字符的urlencode差异(可导致针对特定浏览器的xss),对中文字符的urlencode差异(可到致程序获取参数出错等问题)。这里的浏览器urlencode是指浏览器对输入的某些字符进行自动编码的行为。
需要用到的知识:
1、获取浏览器发送的数据包可以通过burp进行抓取(当然,各个浏览器都有其相应的抓包插件,如火狐的Tamper Data等)。
2、在PHP程序中,获取浏览器发送的请求字符串,即编码后的字符串是通过$_DERVER[‘QUERY_STRING]来实现的。$_GET的值不是实际的请求参数,是讲过url解码后的参数值。
一、不同浏览器对特殊字符的urlencode策略差异
这里的特殊字符,是指可能在注入、跨站等攻击中使用的字符,主要有: ‘ ” ` < > !@$%^&*()[]{}:;.,?~等。注意要测试的特殊字符中没有#,因为#在url中一般作为分片自符使用,query_string是不会接收#后的内容的。一般的防注入系统会对这些特殊字符进行相应的转换。
为了测试,可以在本地的网站中建如下的页面来进行测试:
<?php print 'query_string:'.$_SERVER['QUERY_STRING']; print '<br />'; print '<input type=text value="'.$_SERVER['QUERY_STRING'].'"/>'; print '<br />'; print '$_GET:'.$_GET['a']; ?>
1、在火狐浏览器下输入http://localhost/test1.php?a='”`<>!@$%^*()-_=+{}[]:;.,?/\|~%&
结果如下:
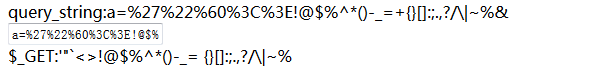
可以看到火狐浏览器将:单引号 双引号 反引号 < >进行了编码,其他特殊字符没有进行相应的编码。还要注意,输入的%没有被火狐浏览器进行编码,而且服务器端也成功的识别为%,即%火狐不会进行编码。但是如果我们输入http://localhost/test1.php?a=%27结果如下:
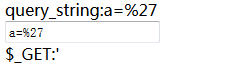
可以看出,火狐没有对%进行url编码,还是输入的形式。但是$_GET却将%27识别为单引号,是因为$_GET是服务器接收的参数解码后的值(%27解码后的值就是单引号)。如果,我们的目的是为了输入一个百分号和数字2和7,为了$_GET接收不会出错,需要手动对%进行url编码(%25)后输入,即输入%2527。结果如下:
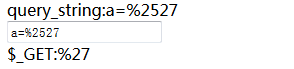
总结:火狐浏览器在特殊字符中只会对'”`<>几个字符进行url编码。%后面跟着两位数字时,服务器会对其进行url解码,解码成相应的字符,如果%后面跟着不是两位数字,那么服务器端不会将其解码成其他数字,还是%。因此,如果我们要通过url中参数向服务器传送一个字符串,而字符串中有%,如果%后面不是两位数字,那么不用任何操作,直接放在url中即可;如果%后面有两位数字,那么为了防止解码出错,需要将%进行编码,即%25。例子:我们需要将一个字符串,如23%cde通过url传送给服务器,那么直接传送即可,在浏览器中输入:localhost/test1.php?a=23%cde,那么$_GET会接收到23%cde,如果要传送如23%27cde这个字符串,就需要在浏览器中输入:localhost/test1.php?a=23%2527cde,这样$_GET才会接收到23%27cde。
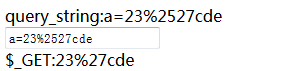
ps:url中的# / &是有特殊含义的,若要想传送这些参数不出错,需要对其进行url编码。
2、在IE浏览器下输入http://localhost/test1.php?a='”`<>!@$%^*()-_=+{}[]:;.,?/\|~%&
![]()
可以看到在IE下,浏览器对任何字符都没有进行编码。
3、在chrome下,输入
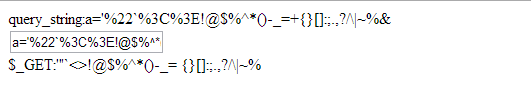
可以看到Chrome浏览器会自动对双引号 < >三个字符进行编码,其他字符都没有进行自动编码。
总结:

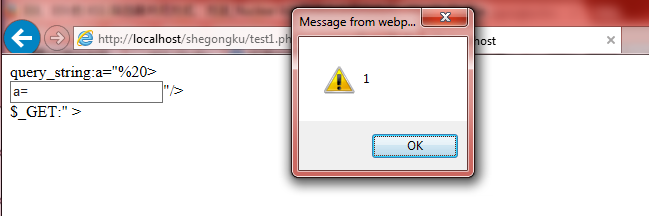
因此,如果服务端直接获取浏览器发送的请求字符串(即浏览器encode后的字符串)并进行输出,可导致IE浏览器下出现XSS,Chrome下出现小范围xss,而火狐则在这种情况下较为安全。如果对上面的PHP代码,中输入a=” ><script>alert(1)</script>,那么IE浏览器下就会出现xss(当然有可能被IE的xss过滤器过滤掉)
![]()
如果关闭IE的xss过滤器(关闭方法参考:http://lcx.cc/?i=2491),那么上述输入就会在IE下产生xss,而在别的浏览器上就没事。
二、浏览器对中文的urlencode差异
浏览器一般情况下会对中文进行url编码,但是对中文的url编码分为utf-8编码和gbk编码。而服务器端通过$_GET接收的接收的值是对查询字符串进行解码后的值,如果解码的方式和浏览器的编码的方式不同,那么服务器就会接收到错误的输入。
ps:下面的例子中还是用的上面的测试代码,且代码文件分为utf-8编码方式和ANSI编码方式。
在火狐下,火狐URL中中文的默认编码方式是可以设置的(在浏览器中输入about:config,然后设置network.standard-url.encode-utf8即可)。在IE下对中文不进行编码,Chrome下默认对中文进行UTF-8编码。
现在我们将火狐一个设为gbk,一个设为utf-8,连同IE和chrome浏览器来看程序返回的结果有什么不同。

总结:IE浏览器对url中中文不进行默认编码,但显示时默认按照gbk显示。
Chrome浏览器对url中中文默认进行UTF-8编码,只有文件是ANSI格式,且输出是gbk时才会出现乱码。
Firefox gbk浏览器对url中中文默认进行gbk编码,且只有在文件是ANSI编码且输出gbk时才正常。
Firefox UTF-8 浏览器对url中中文默认进行UTF-8编码,只要输出为utf-8格式就会显示正常。
当然,上面的比对没有啥实际意义,只是证明了两点:
1、如果不采取措施对$_GET变量进行相应的编码转换,则不可能适用于所有浏览器而不出现乱码。
2、当在PHP程序中不通过header指定输出编码方式时,浏览器的显示编码与服务器PHP文件的编码方式有关。如果PHP程序文件是ANSI编码,浏览器默认以gbk编码方式展示;如果PHP文件是UTF-8编码,则浏览器默认以utf-8编码的方式展示网页。
在实际使用过程中,我们关心的是程序能否正确的接收到用户的输入来进行数据库查询等后续的相关操作。若正确接收到用户的中文输入需要对用户的QUERY_STRING正确的解码成$_GET参数。其实urldecode的解码和程序源代码有关,即如果程序代码是ANSI格式,那么服务器会采用gbk方式对QUERY_STRING进行解码,如果序代码是UTF-8格式,那么服务器会采用UTF-8方式对QUERY_STRING进行解码。
————————————————————————————————————
为了适用所有的浏览器,可能有的人说对接收变量进行编码统一,即通过iconv()函数或mb_convert_encoding()函数来对接收参数进行编码转换,但问题时我们无法知道接收参数的编码,如果不管青红皂白,都通过iconv(“gbk”,”utf-8″,$_GET[‘a’])或mb_convert_encoding($_GET[‘a’],”utf-8″,”gbk”)方式转换接收参数,那么如果$_GET[‘a’]本来就是utf-8编码的话就会出乱码了。因此解决问题的根本办法有一下几种:
1、在程序中识别接收参数的中文编码类型,然后分情况利用iconv()函数或mb_convert_encoding()函数转换即可。
2、不让用户直接在浏览器地址栏中输入中文,而是在页面中让用户输入中文然后转到相应的页面或在页面中嵌入中文的链接让用户点击。这样不会出现乱码的原因是页面中的中文链接是以页面的编码格式发送,而不是浏览器的默认编码方式转换。
<html> <head> <?php print 'query_string:'.$_SERVER['QUERY_STRING']; if(isset($_GET['a'])) print 'get:'.$_GET['a']; ?> <br /> 表格 <br /> <form action="" method="get"> <input type="text" name="a"/> <input type="submit" value="提交" /> </form> </html>
上面代码的话,在程序中不需要进行转换所有页面都会正常的获取$_GET的值。