前言
在之前介绍的流量劫持文章里,曾提到一种『HTTPS 向下降级』的方案 —— 将页面中的 HTTPS 超链接全都替换成 HTTP
版本,让用户始终以明文的形式进行通信。
看到这,也许大家都会想到一个经典的中间人攻击工具 —— SSLStrip,通过它确实能实现这个效果。
不过今天讲解的,则是完全不同的思路,一种更有效、更先进的解决方案 —— HTTPS 前端劫持。
SSLStrip 的缺陷
在过去,流量劫持基本通过后端来实现。但如今 Web 技术日新月异,若只顾及传统的后端,而不把强大的前端技术结合起来,显然无法发挥出最大的威力。
类似大多数安全工具,SSLStrip 也是纯后端实现。因此它只能操控最原始的流量数据,严重阻碍了向更高层次的发展。
和大多数后端实现的中间人工具一样,SSLStrip 同样面临着众多的挑战:
- 动态元素怎么办?
- 如何处理数据包分片?
- 性能消耗能否降低?
- ……
动态元素
在 Web 刚出现的年代里,SSLStrip 这样的工具还是大有用武之地的。那时的网页都以静态为主,结构简单层次清晰。在流量上进行替换,完全能够胜任。
然而,如今的网页日益复杂,脚本所占比重越来越多。如果仅仅从流量上着手,显然力不从心。
var protocol = 'https';
document.write('<a href="' + protocol + '://www.alipay.com/">Login</a>');
即使非常简单的动态元素,后端也毫无招架之力。
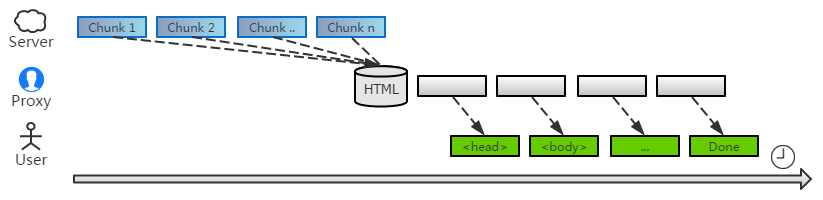
分片处理
分块传输的道理大家都明白。对于较大的数据,一口气是无法传完的。客户端依次收到各个数据块,最终才能合并成一个完整的网页。
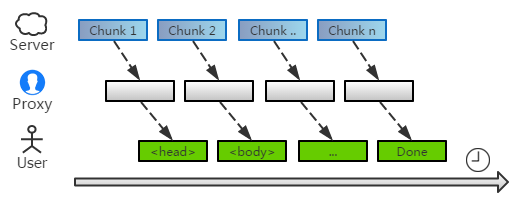
由于每次收到的都是残缺的碎片,这给链接替换带来很大的麻烦。为了能顺利进行,中间人通常先收集数据,等到页面接收完整,才开始替换。
如果把数据比作水流,这个代理就像大坝一样,拦截了源源不断往下流的水,直到蓄满了才开始释放。因此,下游的人们需忍受很久的干旱,才能等到水源。
性能消耗
由于 HTML 兼容众多历史遗留规范,因此替换工作并非是件轻松事。
各种复杂的正则表达式,消耗着不少的 CPU 资源。尽管用户最终点击的只是其中一两个链接,但中间人并不知道将会是哪个,因此仍需分析整个页面。这不得不说是个悲哀。
前端的优势
如果我们的中间人能打入到页面的前端,那么情况会不会有所改善呢?
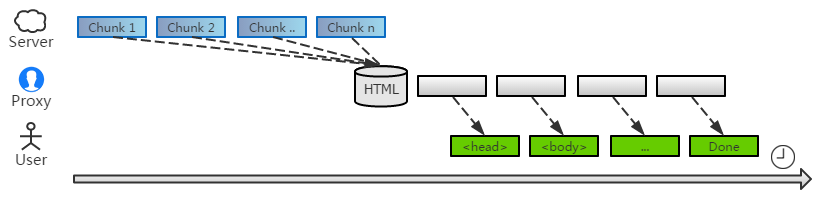
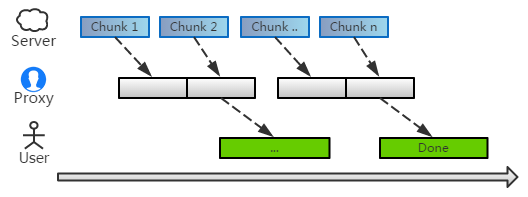
分片处理
首先,要派一名间谍到页面里。不过这是非常容易办到的:
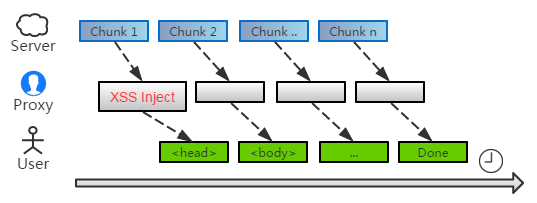
不像超链接遍布在页面各处,脚本插入到头部即可运行了。
所以我们根本不用整个页面的数据,只需改造下第一个 chunk 就可以,后续的数据仍然交给系统转发。因此,整个代理的时间几乎不变!
动态元素
很好,我们轻易渗透到页面里。但接着又如何发起进攻?
既然到了前端里,方法就相当多了。最简单的,就是遍历超链接元素,将 https 的都替换成 http 版本。
这个想法确实不错,但仍停留在 SSLStrip 思维模式上。还是替换这条路,只是从后端搬到前端而已。
尽管这个方法能胜任大多场合,但仍然不是最完美的。我们并不知道动态元素何时会添加进来,因此需要开启定时器不断的扫描,才不至于遗漏。这显然是个很挫的办法。
性能优化
事实上,超链接无论是谁产生的、何时添加进来的,只要不点击,都是不起作用的。所以,我们只需关心何时去点击就可以 —— 如果我们的程序,能在点击产生的第一时间里控制住现场,那么之后的流程就可由我们决定了。
听起来似乎很玄乎,不过在前端,这只是小菜一碟的事。点击,不过个事件而已。既然是事件,我们用最基础的事件捕获机制,即可将其轻松拿下:
document.addEventListener('click', function(e) {
// ...
}, true);
DOM-3-Event 是个非常有意义的事件模型。之前用它来实现『内联 XSS 拦截』详细,如今同样也可以用来劫持链接。
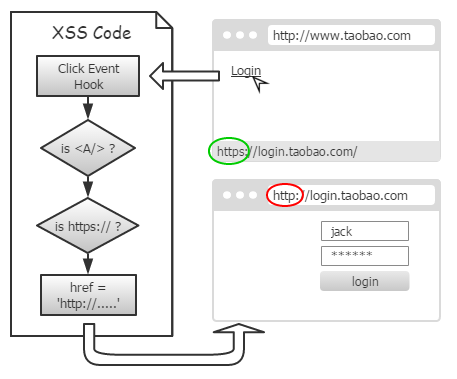
我们捕获全局的点击事件,如果发现有落在 https 超链接上,果断将其 —— 拦截?
如果真把它拦截了,那新页面就不会出现了。当然你会说,可以自己 window.open 弹一个,反正点击事件里是可以弹窗的。
不过,请别忘了,并非所有的超链接都是弹窗,也有不少是直接跳转的。你会说可以修改 location 来实现。
但要识别是『弹窗』还是『跳转』,并不简单。除了超链接的 target 属性,页面里的 <base> 元素也会有影响。当然,这些相信你都能办到。
然而,现实未必都是那么简单的。有些超链接本身就绑定了 onclick 事件,甚至在其中 return false 或 preventDefault,屏蔽了默认行为。如果我们不顾及这些,仍然跳转或弹窗,那就违背页面的意愿了。
事实上,有一个非常简单的办法:当我们的捕获程序运行时,新页面还远没出现,这时仍可以修改超链接 href 属性。待事件冒泡完成、执行默认行为时,浏览器才读取 href 进行访问。
因此,我们只需捕获点击事件,修改超链接地址就可以了。至于是跳转、弹窗、还是被屏蔽,根本不用我们关心。
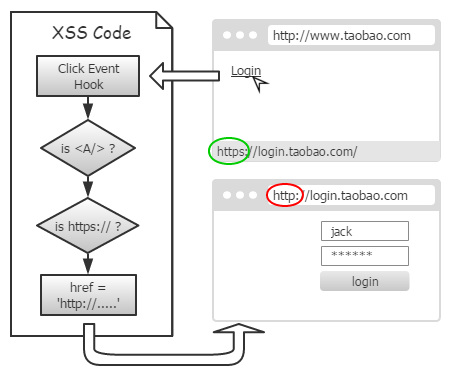
就那么简单。因为我们是在用户点下去之后才修改,所以浏览器状态栏里,显示的仍是原先 https !
当然,点过一次之后,再把鼠标放到超链接上,状态栏里显示的就是修改后的了。
为了能继续忽悠,我们在修改 href 之后的下个线程周期里,把它改回来。因为有了一定延时,新页面并不受影响。
var url = link.href;
link.href = url.replace('https://', 'http://');
setTimeout(function() {
link.href = url;
}, 0);
这样,页面里的超链接始终都是正常的 —— 只有用户点下的瞬间,才临时伪装一下。
更多拦截
除了通过超链接,还有其实方式访问页面,我们应尽可能多的进行监控。例如:
- 表单提交
- window.open 弹窗
- 框架页面
- …..
表单提交
表单提交和超链接非常类似,都具有事件,只是将 click 换成 submit,href 换成 action 而已。
脚本弹窗
函数调用的最简单了,只需一个小钩子即可搞定:
var raw_open = window.open;
window.open = function(url) {
// FIX: null, case insensitive
arguments[0] = url.replace('https://', 'http://');
raw_open.apply(this, arguments);
}
框架页面
因为我们把 https 页面变成 http 了,但里面的框架地址仍是原先的。由于协议不同,这就产生了跨域问题,导致页面无法正常工作了。所以我们要做的,就是把页面里的框架,也都转型成 http 版本,保证能和主页面融为一致。
但框架不同于之前,它是自动加载的。如果等到框架加载完了再去处理,说不定已经开始报跨域错误了,而且还白白的浪费一次加载流量。因此,我们必须让框架一出现,还没来得及加载,就立即替换掉它的地址。
这在过去是个很棘手的问题,然而 HTML5 时代给我们带来了新希望 —— MutationEvent。用它即可实时监控页面元素,之前也尝试过一些试验。
解决了框架页的问题,我们就能成功劫持支付宝登录页的账号框 IFrame 了!
后端配合
通过前端的 XSS 脚本,我们轻易解决了过去各种棘手的问题。但挑战并未就此结束,我们仍面临着众多难题。
如何告诉代理
尽管在前端上面,我们已经避开了各种进入 https 的途径,让请求以明文的形式交给代理。但代理又如何决定,这个请求用 https 还是 http 转发呢?
传统的后端劫持之所以能正确转发,那是在替换超链接的时候,已经做下记录。当出现记录中的请求,就走 https 的转发。
而我们的劫持在前端,并且只发生在点击的一瞬间。即使马上去告诉中间人,某个 URL 是 https 的,这时也来不及了。
告诉中间人是必须的。但我们可以用一个巧妙的方法,不必单独发送消息 —— 我们只需在『向下转型』后的 URL 里,做一个小记号。
当代理发现请求的 URL 里有这个记号,它自然就懂了,直接走 https!

由于把页面从 https 降级到了 http,因此页面发起请求的 referer 也变成 http 版了。所以,中间人应尽量把 referer 也修正回来,避免被服务器发觉。
隐藏伪装
不过,这也有一定的缺陷。用户点开的安全页面,地址栏里会出现我们的特殊记号。当然,我们可以使用看似很正常的字符,例如 ?zh_cn、?utf_8,?from_baidu 等等,起到更好的伪装。
如果你觉得还是不满意,也可以让这些碍眼标记尽快消失:
if url has symbol history.replaceState(..., clear_symbol(url) )
HTML5 各种强悍的功能,这下都可以在前端利用起来了。
重定向劫持
当然,光靠前端的劫持,还是远远不够的。现实中,还有另一种很常见的方式,那就是重定向到安全页面。
仔细回想下,平时我们是怎样进入想上的网站的。例如支付宝,除非你有收藏,否则就得自己敲入 www.alipay.com 或 www.zhifubao.com,当你回车进入时,浏览器又如何知道这是个 HTTPS 的网站呢?
显然,第一个请求仍是普通的 HTTP 协议。当然,这个 HTTP 版的支付宝的确存在,它的唯一功能就将用户重定向到 HTTPS 版本。
当我们的中间人一旦发现有重定向到 HTTPS 网站的,当然不希望用户走这条不受自己控制的路。于是拦下这个重定向,然后以 HTTPS 的方式,获取重定向后的内容,最后再以 HTTP 明文的方式,回复给用户。
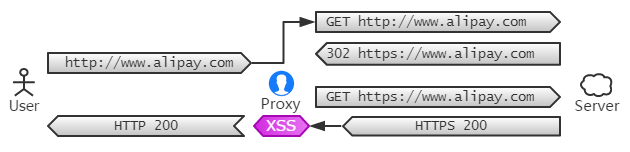
因此在用户看来,始终处于 HTTP 网站上。
不过,如今的 Web 里增加一个新的安全标准:HTTP Strict Transport Security。如果服务器返回了这个头部,之后一定时间内访问该站点,始终通过 HTTPS 的方式。
所以我们的中间人一旦发现这个头,就得果断将其删除。
当然,直接敲网址的并不常见。大多都是搜索引擎,然后直接从第一个结果里进来了。
比较悲剧的是,国内的搜索引擎几乎都是 HTTP 的。在用户访问搜索页面的时候,我们的 XSS 早已潜伏在其中了,因此从中点出来的任何一条结果,都是进不到官方的 HTTPS 里的。
除了搜索页面,不少类似 hao123 之类的网址大全,也未开启 HTTPS。因此从中导流的网站,都面临着被中间人劫持的风险。
防范措施
介绍了攻击方法,接着讲解防御措施。
脚本跳转
事实上,无论是前端劫持还是后端过滤,仍有不少的网站无法成功。例如京东的登录:
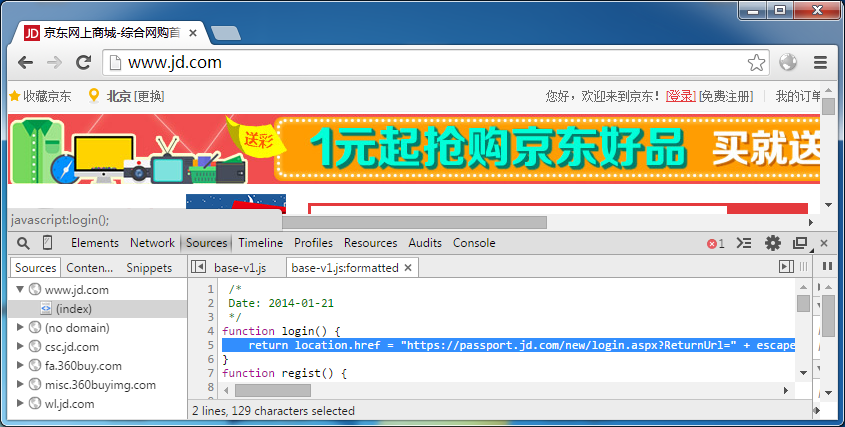
它是通过脚本跳转到 HTTPS 地址的。而浏览器的 location 是个及其特殊的属性,它可以被屏蔽,但无法被重写。因此我们难以控制页面的跳转情况。
如果非要劫持京东页面,我们只能使用白名单的方式,特殊对待该站点。但这样就大幅增加了攻击成本。
混淆明文
当然,不难发现京东的登录脚本里,URL 是以最直白的明文出现的。所以我们利用 SSLStrip 的方式,对脚本里的『https://』进行替换,也能起到一定的作用,至少对京东这个案例就能通过。
但对于稍微复杂一点的脚本,URL 是通过字符串各种操作拼接而成的,那么就难以实施了。所以在安全需要较高的场合,不妨把一些重要的地址进行简单的混淆,中间人就无法使用通用的方式来攻击,必须进行特殊对待,从而提高实施成本。
尽可能多的 HSTS
之前提到 HSTS 头。只要这个字段出现过一次,那么浏览器很长时间内都会只用 HTTPS 访问站点。因此,我们尽可能多的开启 HSTS。
现实中的劫持并非都是 100% 成功的,上述提到,使用脚本跳转就会有遗漏。所以,只要用户出现一次遗漏,那么之后劫持就彻底失效了。
攻击演示
因为是前端劫持,所以 Demo 有两个文件:一个前端代码,另一个后端脚本(NodeJS)
https://github.com/EtherDream/https_hijack_demo
相比之前写的流量劫持演示,这里功能更为专一,不再提供额外的劫持途径(例如 DNS 等)。
想测试也非常简单,只需配置浏览器代理,即可模拟 HTTP 的劫持:
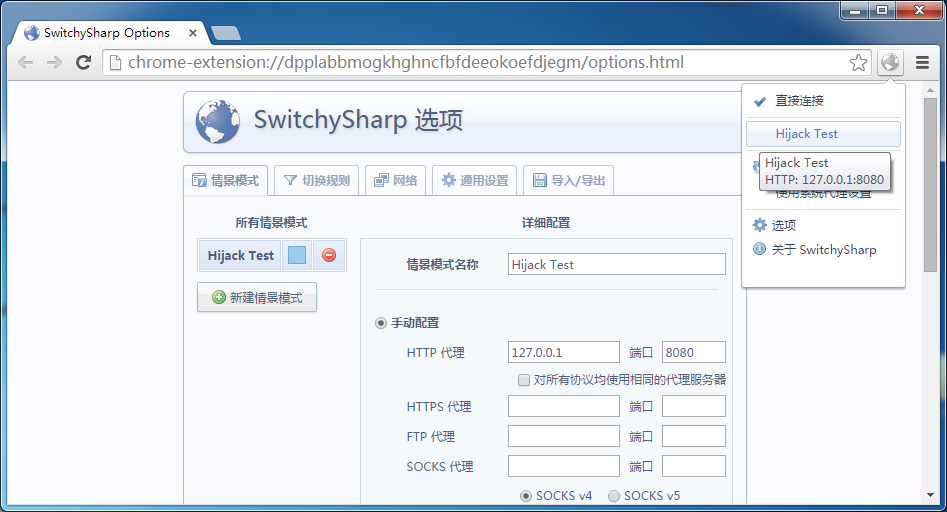
不嫌麻烦的话,也可以在 Linux 内核的系统上测试,转发 80 到本机即可。原理都是一样的。
我们随便找一个 HTTP -> HTTPS 的登录网站测试。
得益于前端脚本的优势,我们把鼠标放到登录超链接上,状态栏显示的仍是原始 URL:
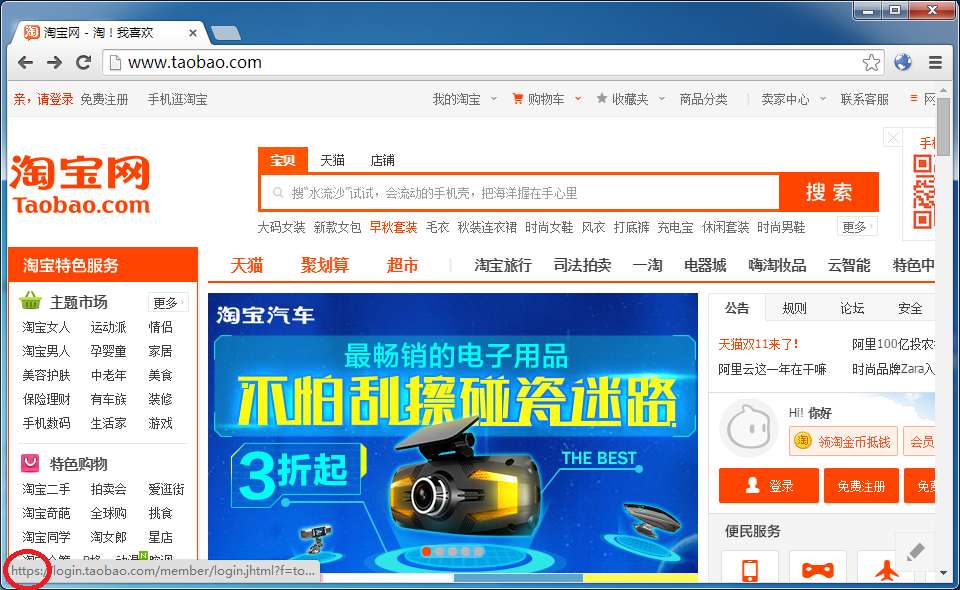
在我们点击的瞬间,暗藏页面中的 XSS 钩子触发了,成功把我们带到中间人虚拟的 HTTP 登录页面里。
当然,由于 URL 参数很多,最后的那个记号看不到了。
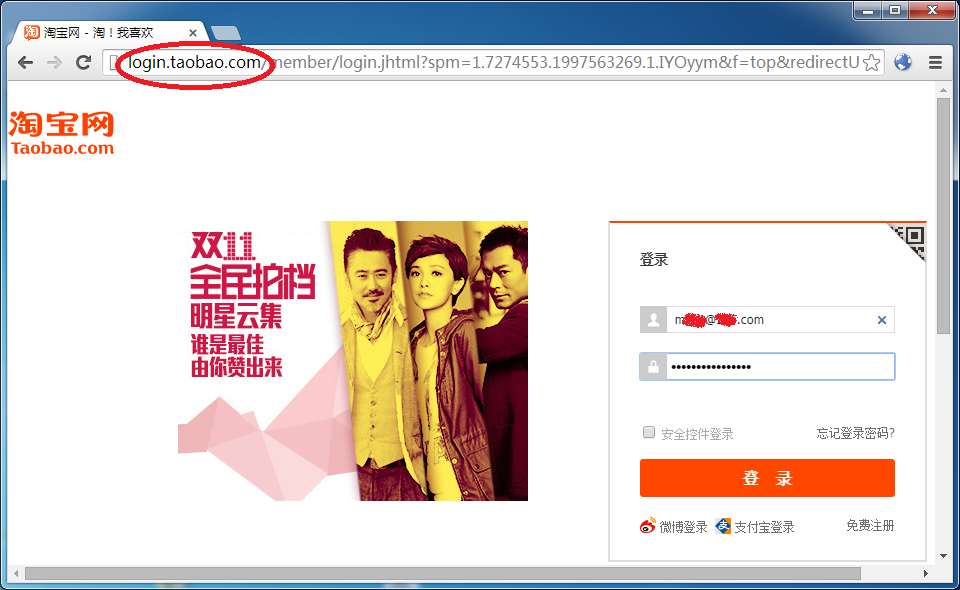
由于淘宝的登录页面未进行地址判断,我们的降低后的页面仍然能登录成功。
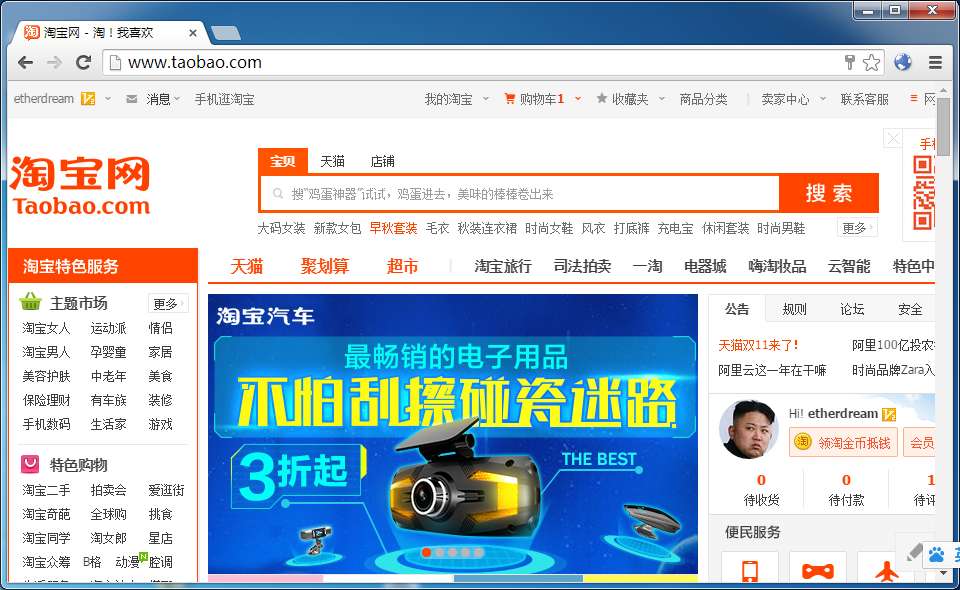
当然之前也说了,并非所有的页面都能劫持成功。
如今越来越多的网站都已重视,因此前端的安全性检测也随之而生。仅仅通过一个工具,实现大规模通用化的劫持,未来会更加困难。
但先比传统的纯后端实现,前后结合的方案能够带来更大的发挥空间。
转自:http://www.cnblogs.com/index-html/p/ssl-frontend-hijack.html
ps:文章的主要内容是指不通过后端方式而是采用前端方式来进行类似SSLStrip的方式将HTTPS替换成http,来达到劫持的目的。前端劫持时按不同的跳转方式采用下面几种方式:
(1)通过点击进行跳转。方式是对click事件进行监听,利用事件捕获机制进行替换。即替换点击中链接的src属性、target属性等。
document.addEventListener('click', function(e) {
// ...
}, true);
var url = link.href;
link.href = url.replace('https://', 'http://');
setTimeout(function() {
link.href = url;
}, 0);
(2)表单提交。表单提交和超链接的方式类似,只是将click事件换成submit事件,href换成action即可。
(3)脚本弹窗(window.open弹窗)。采用钩子的方式解决
var raw_open = window.open;
window.open = function(url) {
// FIX: null, case insensitive
arguments[0] = url.replace('https://', 'http://');
raw_open.apply(this, arguments);
}
(4)框架页面。对于框架采用html5中的MutationEvent,用它来实时监控页面元素。
(5)页面302重定向。对于302重定向到https进行拦截并,并将页面内容以http的方式返回给客户端,状态变为200。当然,如果网站头中有HSTS头时,需要将其去掉。
(6)其他情况要进行正则替换或按照网站采取不同的方法。
前端将https替换成http后,为了让后端知道页面原先是https的还是http的,我们可以在上面采用的替换方式中对替换后的链接加入相应的标识来标明链接本来就是http的还是被我们前端替换成为http的。
—————————————————————————————————————
想到的应用:
ps:
SSLStrip 终极版:Location 瞒天过海
前言
之前介绍了 HTTPS 前端劫持 的方案,虽然很有趣,然而现实却并不理想。其唯一、也是最大的缺陷,就是无法阻止脚本跳转。若是没有这个缺陷,那就非常完美了 —— 当然也就没有必要写这篇文章了。
说到底,还是因为无法重写 location 这个对象 —— 它是脚本跳转的唯一渠道。尽管也流传一些 Hack 能勉强实现,但终究是不靠谱的。
事实上,在最近封稿的 HTML5 标准里,已非常明确了 location 的地位 —— Unforgeable。
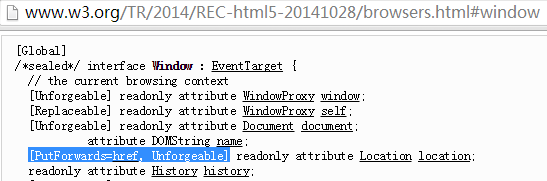
这是个不幸的消息。不过也是件好事,让我们彻底打消各种偏门邪道的念头,寻求一条全新的出路。
替换明文 URL
上回也提到,可以参考 SSLStrip 那样,把脚本里的 HTTPS URL 全都替换成 HTTP 版本,即可满足部分场合。
当然,缺陷也是显而易见的。只要 URL 不是以明文出现 —— 例如通过字符串拼接而成,那就完全无法识别了,最终还是无法避免跳转到 HTTPS 页面上。
这种情况并不少见,所以我们需要更先进的解决方案。
替换 location
尽管我们无法重写 location,但要山寨一个和 location 功能一样的玩意,还是非常容易的。我们只需定义几个 getter 和 setter,即可模拟出一个功能完全相同的 location2。但如何将原先的 location 映射过来呢?
这时,后端的作用就发挥出来了。类似替换 HTTPS URL,这次我们只关注脚本里的 location 字符,把它们都改成 location2 —— 于是所有和地址栏相关的读写,都将落到我们的代理上面。之后能做什么,不用说大家也都明白吧。

- 代理所有的 setter:如果跳转到 HTTPS 就将其拦下,然后降级到 HTTP 版本上。
- 代理所有的 getter:如果当前处于降级的页面,我们将返回的路径都还原 HTTPS 字符,即可骗过协议判断脚本,让那些自检功能彻底失效!
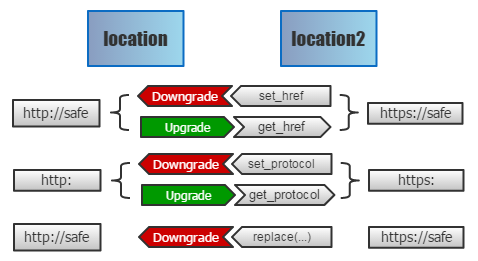
相比之前的 URL 替换,这个方案完美太多 —— URL 是动态创建的非常普遍,但 location 不是明文出现的,及其罕见。
除非脚本是加密过的,否则即使用 Uglify 那样的压缩工具,也不会把全局变量给混淆。至于人为刻意去转义它,更是无稽之谈了。
if (window['loc\ation'].protocol != 'https:') {
// ...
}
到此,我们的目标已经明确了:
- 前端:实现一个 location 代理。
- 后端:将脚本里出现的 location 替换成代理变量名。
处理外链脚本
虽然替换页面脚本的内容并不困难,但对于外链脚本,那就不容乐观了。
现实中,不少页面外链了 HTTPS 绝对路径 的脚本。这时,我们的中间人就无能为力了。为了避免这种情况,我们仍需替换页面里的 HTTPS URL,让中间人能掌控更多的资源。

要替换 URL 倒也不难,一个简单的正则就能实现 —— 但既然使用正则,我们面对的只能是字符串了。
然而事实上,收到的都是最原始的二进制数据,甚至未必都是 UTF-8 的。在上一篇文章里,我们为了简单,直接使用二进制的方式注入。但在如今,这个方法显然不可行了。
使用二进制,不仅难以控制,而且很不严谨。我们很难得知匹配到的是独立的字符,还是一个宽字符的部分字节。因此,我们还是得用传统可靠的方式来处理字符串。
处理字集编码
我们得借助字集转换库,例如大名鼎鼎的 iconv,来协助完成这件事:
- 首先将二进制数据转换成 UTF-8 字符串
- 有了标准的字符串,我们的正则即可顺利执行了
- 将处理完的字符串,重新换回先前的编码
尽管这一来一回得折腾两次,性能又得耗费不少,但这仍是必须的。
事实上,这个过程也不是想象的那么顺利。有相当多的服务器,并没有在返回的 Content-Type 里指定编码字集,于是我们只能尝试从页面的 <meta> 中获取。
但这个标签兼容诸多规范,例如过去的:
<META HTTP-EQUIV="Content-Type" CONTENT="text/html; CHARSET=GBK">
以及如今流行的:
<meta charset="GBK" />
尽管通过正则很容易获取,但用正则的前提还是得先有字符串,于是我们陷入了僵局。
不过好在标签、属性、字集名,基本都是纯 ASCII 字符,所以可先将二进制转成默认的 UTF-8 字符串,从中取出字集信息,然后再进行转码。
处理数据分块
得益于丰富的第三方扩展,上述问题都不难解决。
然而,之前提到过『前端劫持』的一个巨大优势 —— 无需处理所有数据,只需在第一个 chunk 里注入代码即可。但现在,这项优势面临着严峻的考验。
我们要替换页面里的 HTTPS 资源、location 变量等等,它们会出现在页面的各个位置。如果我们对每个 chunk 进行单独过滤、转发,这样会有问题吗?
现实中,未必都是这样理想的 —— 总会有那么一定的几率,替换的关键字正好跨越两个 chunk:
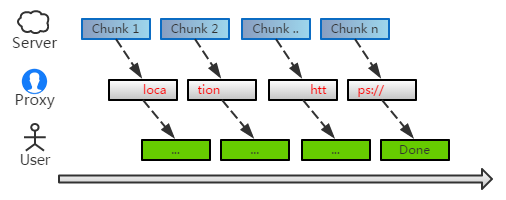
这时候,残缺的首尾都无法匹配到,于是就会出现遗漏。关键字越长,出现的几率也就越大。对于 URL 这样长的字符串来说,这是一个潜在的隐患。
要完美解决这个问题,是比较麻烦的。不过有个简单的办法:我们可以扣留下 chunk 末尾部分字符,拼接到下个 chunk 的之前,从而降低遗漏的可能。
当然,如果不考虑用户体验的话,还是收集完所有数据,最后一次性处理,最省事了。
事实上还有更好的方案:中间人开启一个缓冲区,将收到数据暂时缓存其中。当数据积累到一定量、或者超过多久没有数据时,才开始批量处理缓存队列。
这样就可以避免 频繁的 chunk 上下文处理,同时也 不会长时间阻塞用户的响应时间,自然是两全其美的。
这是不是有点类似 TCP nagle 的味道呢。
前端 location 代理
讲完了后端的相关细节,我们继续回到前端的话题上。
实现一个 location 的代理很简单,不过值得留意的细节倒是不少:
- location 不仅存在于
window,其实document里也有个相同的。 - location 对象本身也是可以被赋值的,效果等同于 location.href。(
[PutForwards=href, ...]已经很好的解释了) - 同理,location 的
toString返回的也是href属性。 - 如果带有 location2 的脚本被缓存住了,那么用户在没有劫持的页面里,也许就会报错。所以还得留一条兼容的后路。
- ……
只要考虑充分,实现一个 location 的切面还算是比较容易的。
动态脚本劫持
前面谈到替换页面的 HTTPS URL,以确保外链脚本明文传输。
然而现实中,并非所有脚本都是静态的。如今这个脚本泛滥的时代,动态加载模块是很常见的事。如果引入的是一个 HTTPS 的脚本,那么我们的中间人又无从下手了。
不过值得庆幸的是,模块拦截不像 location 那样无法实现。现实中,有非常多的方法可以拦截动态模块。在之前写的《XSS 前端防火墙 —— 可疑模块拦截》 一文里,已经详细讨论过各种方法和细节,这里正好派上用场。
事实上,除了脚本外,框架页同样也存在这个问题。上一篇文章里,我们采用 CSP 来阻挡 HTTPS 的框架页。但那仅仅是屏蔽,并不是真正意义的拦截。只有加上如今这套钩子系统,才算一个完善的拦截系统。
演示
说了那么多,真正的核心无非就是改变脚本里的 location 变量而已,其他的一切都只是为了辅助它。
下面我们找几个之前无法成功的网站,试验下这个加强版的劫持工具。
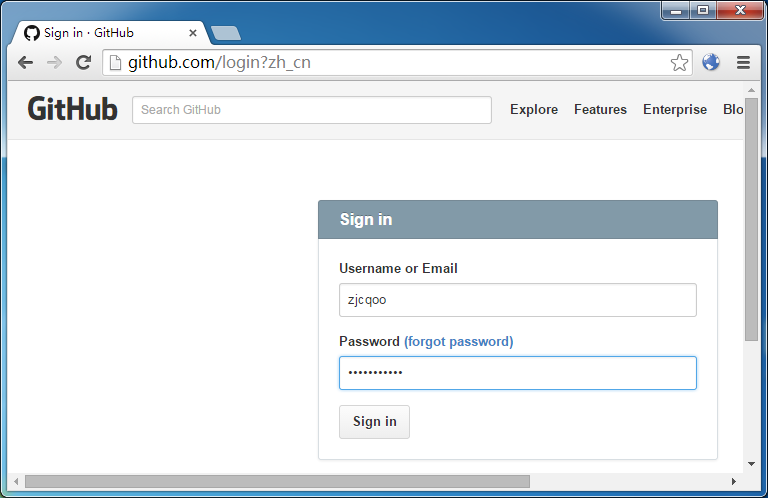
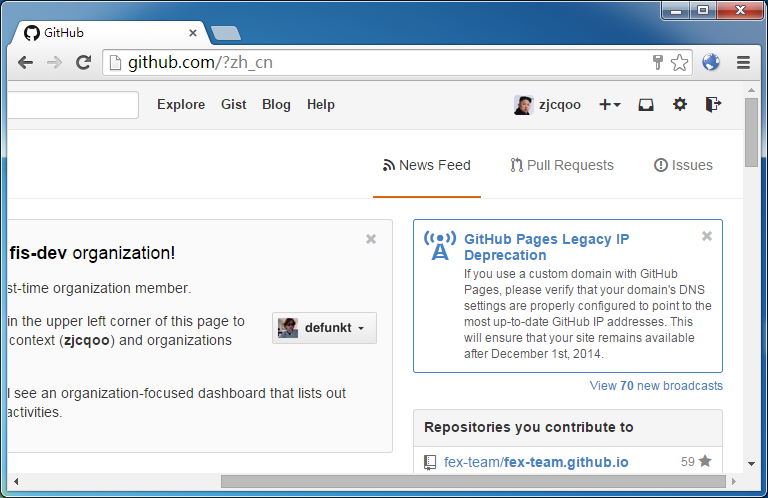
上一篇文章里提到京东登录,就是通过脚本跳转的。我们首先就拿它测试:
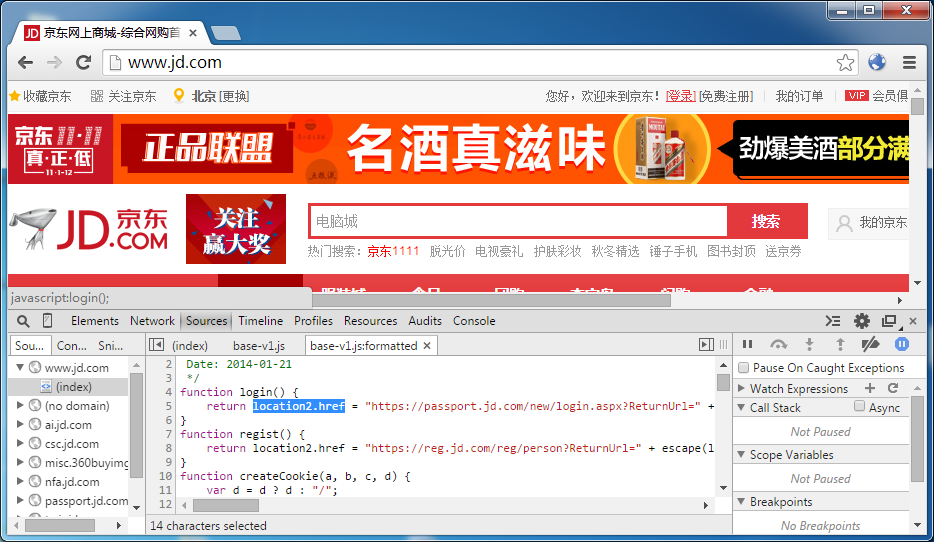
当流量经过中间人代理,页面和脚本里的 location 都变成了我们的变量名。于是之后和地址栏相关的一切,尽在我们的掌控之中了:
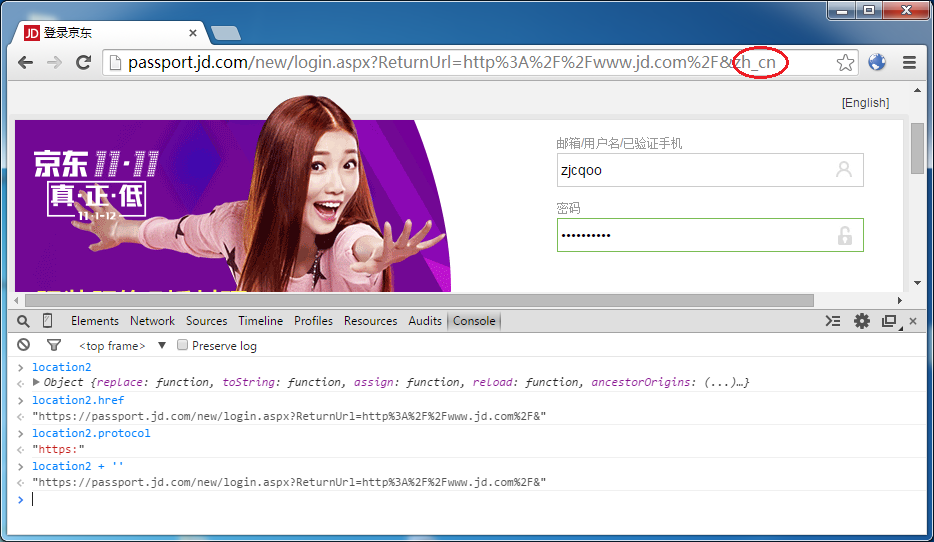
注意地址栏里有一个 zh_cn 的标记,那正是 URL 向下转型后的识别暗号。
通过 location2 获取到的一切属性,看起来就像在 HTTPS 页面上一模一样。即使脚本里有自检功能,也会被我们的虚拟环境所欺骗。
点击登录,自然是成功的。

毕竟,HTTPS 和 HTTP 只是传输上的差异。在应用层上,页面是无法知晓的 —— 除了询问脚本的 location,但它已被我们劫持了。
除了京东的脚本跳转,财付通网站则是通过非主流的 <meta http-equiv="refresh"> 进行的。
好在我们对页面里的 HTTPS URL 都替换了,所以仍然能够跳转到降级后的页面:
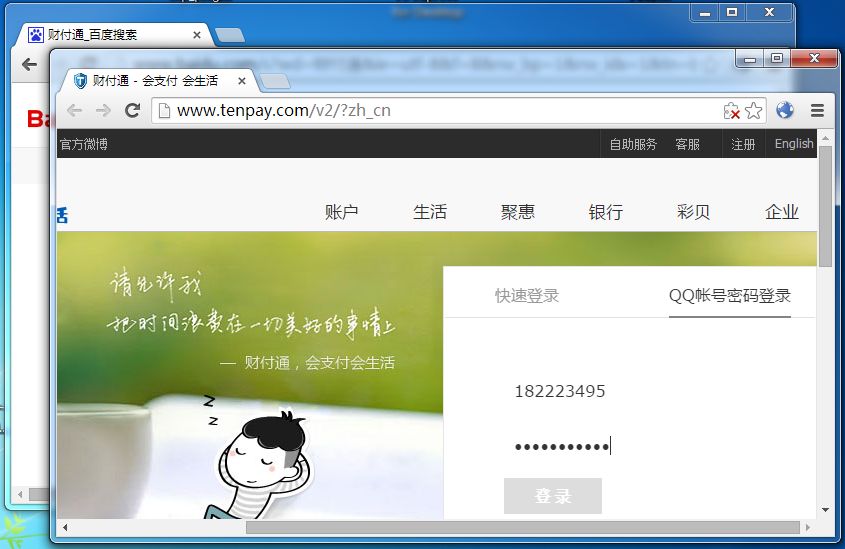
值得注意的是,如果是从 QQ 图标里点进来的,那么页面就直接进入 HTTPS 版本,就不会被劫持了。但从第三方过来那就听天由命了。
由于一般开发人员的思维,是不可能转义 location 这个变量的。因此这套方案几乎可以通杀所有的安全站点。
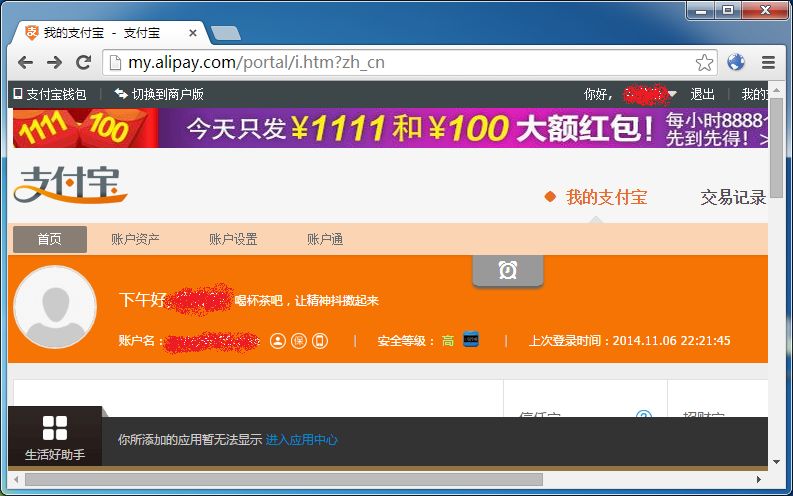
当然,外国的网站也是一样的。只要之前没有被 HSTS 所缓存,劫持依旧轻松自如。
……
所以,只要发挥无尽的想象,实现一个工程化的通用劫持方案,依然是可行的。
防范措施
如果你是仔细看完本文的话,应该早就想到如何应对了。
事实上,由于 JS 具有超强的灵活性,几乎无法从静态源码推测运行时的行为。
因此,只要将涉及 location 相关操作,进行简单的转义混淆,就能躲过中间人的劫持了。毕竟,要在劫持流量的同时,还要对脚本进行语法分析,这个代价不免有点大了。
转自:http://www.cnblogs.com/index-html/archive/2014/11/09/sslstrip-plus.html
转载请注明:jinglingshu的博客 » (SSLStrip的未来——HTTPS 前端劫持)及(SSLStrip 终极版:Location 瞒天过海)