转自:http://zone.wooyun.org/content/17471
0x00 Hash简介与背景
这篇主要是最近准备做的一个研究的笔记, 还有几篇都是事前准备用的,过几天就放出来,搞完这个研究就开始填前面的坑。
我不谈加密,这次主要说说hash在恶意软件对抗上的应用。
Hash其实大部分人都知道是什么,通过把任意长度的输入,通过散列算法变换成固定长度的输出,比如MD5,相同的数据拥有相同的hash值,但 是只要有一个字节不同,hash值的就会有很大的不同,比如1 和 11的hash值,我们调用python的hashlib库看看:
hashlib.md5('字符串).hexdigest()
C4ca4238a0b923820dcc509a6f75849b
6512bd43d9caa6e02c990b0a82652dca
实在没明白也没关系,只需要简单的将hash值看做一个独有的标示,就跟每个人的名字一样,但是世界上没有一模一样的人,却可以有一模一样的数据,比如1和另一个1,所以他们就会有同一个名字,就是hash值。
Hash值后来被大规模应用于安全行业,因为有了一种手法可以很简单的比对两个文件是否一样,但是随着攻防的升级,也出现了大量的问题,因为只需 要修改一个字节hash值就会存在很大的不同,当一个恶意软件被捕获到同时下发了软件的HASH值,淫荡的黑客只要简单的修改自己的恶意软件就能逃过基于 HASH特征库的检测。
所以就有人不断提出新的方法改进。
0x01 imphash
imphash,全称是 import hash, 由mandiant团队提出,关于这个团队,简单来说就是火眼出了10亿美金买了它。
当一个恶意软件可以轻易变形来改变自身的hash值的时候我们该怎么办,一种思路就是找出一个不可轻易变化的地方。
很简单的一个思路,就是函数调用,思考一个简单的Python代码
import re
string = open('1.txt','r').read()
print re.split(‘fuck’,string)
假设我们变换下位置,他还能运行吗?
import re
print re.split('fuck',string)
string = open('1.txt','r').read()
显然是不能,我们就可以根据固定的函数调用的顺序得出一个hash值,用逗号分隔。
hashlib.md5('open,read,re.split').hexdigest()
'cede3925093e8c4ae890db52fe134fd7'
那么我们怎么在恶意软件中使用呢,windows程序有一个叫IAT的东西,里头储存了程序要调用的外部函数地址,这些东西储存在PE头中,我们可以通过读取pe头中的信息得到一个程序的函数调用。
mandiant团队将取imphash的函数封装进了一个python库中 pefile(http://code.google.com/p/pefile/) 。(pefile的详细介绍地址:https://pypi.python.org/pypi/pefile)。
pefile下载地址:http://pefile.googlecode.com/files/pefile-1.2.10-139.tar.gz。
安装:python setup.py install
我们写一个简单的实例:
pe = pefile.PE("C:\\Users\\track\\Desktop\\jd-gui.exe")
a = pe.get_imphash()
print "Import Hash: %s" % a
然后看看pe的值中的 DIRECTORY_ENTRY_IMPORT (也就是函数导入表),可以清晰的看到调用的dll和函数名。
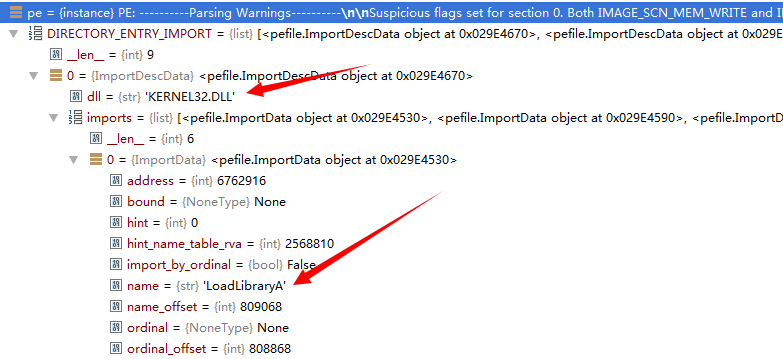
接着我们就可以得到一串hash值:
Import Hash: aef8545505e6e41d4c8eae00ea8de615
0x02 相似度
但是似乎又不太完美,假设恶意软件出了个新功能,简单的加了几个函数,我们有没有可能得出一个值计算两个函数表的相似度呢。
我们可以简单改进一下,假设两个恶意软件的相似度与其顺序并无太大关系,只与函数的个数与是否使用了相同的函数有关,那么问题就变得简单了很多,现在我们将恶意软件调用的函数单独转换为一个hash值,最后由各个hash组成一个数组,然后再写出公式
相识度 =
f(hash数组1 , hash数组2) = 共同出现的函数*2 / (数组1的长度 + 数组2 的长度)
接着我们可以写出代码:
import hashlib
def fuckHash(hash,hash1):
icount = 0.00
for i in hash:
if i in hash1:
icount+=1
fHash = float(icount*2 /(len(hash)+len(hash1)))
return fHash
def hashList(list):
result = []
for i in list:
result.append(hashlib.md5(i).hexdigest())
return result
我们可以将两个经过hashlist函数处理过后的两个hash数组放入fuckHash,计算其相似度。
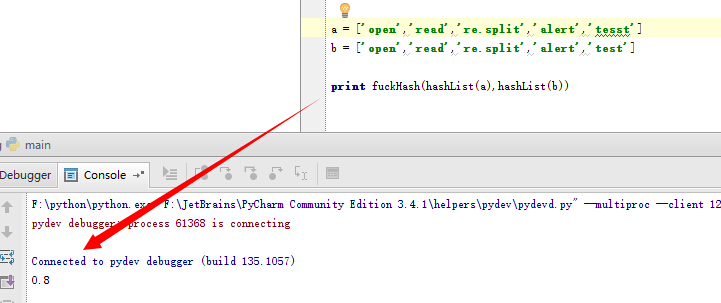
我们简单来试试看,通过a和b两个函数数组计算。
a = ['open','read','re.split','alert','tesst'] b = ['open','read','re.split','alert','test'] print fuckHash(hashList(a),hashList(b))
0x03 序列相似度
这样同时出现了一个问题,imphash的本意就没了,imphash的本意在于拥有相同顺序的函数调用表应该是编译于同一份源码,那么如果要谈改进的 话,那么改进的目的应该是拥有相似函数调用表的恶意软件应该是编译与同一份源码,同时还伴随一个问题,假设两个函数列表 a,b,c,d 和 b,d,c,a 看起来完全是两个东西,但是他喵的经过计算后的概率是100%。
所以我们需要一种计算序列相似度的方式,但是假设我们通过迭代的方式逐个进行序列匹配,计算量好像太大了,是否可以通过一种简单的方式快捷方便的计算相似度?首先我们要知道的是我们计算的是函数调用,我先拿python代码做假设。
import re
string = open('1.txt','r').read()
print re.split('fuck',string)
我们都知道 open 和 read , readlines, readline 在上下文共同出现的概率很大,但是re.split则不一定。那么我们则做出假设 一个函数只与后一个函数有可能成为序列关系。
就是说函数数组 a,b,c,d,f 和 a,b,c,d,e,我将 ab ,bc,cd,df 与 ab,bc,cd,de 进行匹配,就是说
sig(Hash(F(i) +F(i+1)) / (function.length -1 + function1.length -1)
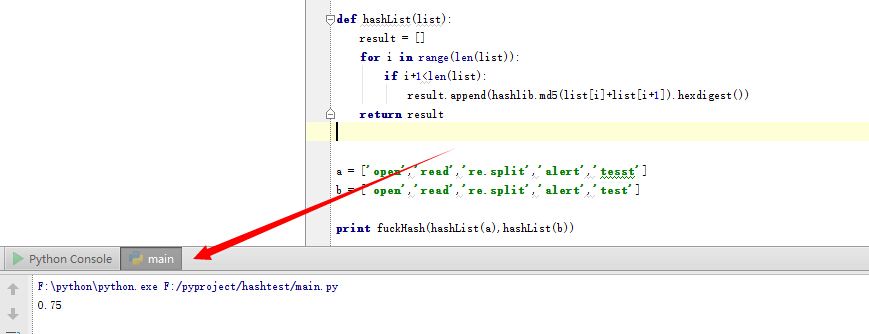
这么写感觉怪怪的,算了,上代码吧,我们只需要简单的修改hashlist
def hashList(list):
result = []
for i in range(len(list)):
if i+1<len(list):
result.append(hashlib.md5(list[i]+list[i+1]).hexdigest())
return result
将两个函数合并为一个hash 。
ps:pefile读写PE文件可以参考:
转载请注明:jinglingshu的博客 » Hash在安全方面的应用与pefile模块